Leveraging Attention Mechanisms for Accurate Binding Site Identification in Drug Discovery
This article provides a comprehensive guide for researchers and drug development professionals on implementing attention mechanisms for protein-ligand binding site identification.
Leveraging Attention Mechanisms for Accurate Binding Site Identification in Drug Discovery
Abstract
This article provides a comprehensive guide for researchers and drug development professionals on implementing attention mechanisms for protein-ligand binding site identification. It covers the foundational principles of attention-based models, explores their transformative advantages over traditional methods, and details practical implementation strategies using cutting-edge architectures like graph transformers and cross-attention. The content further addresses critical troubleshooting for common faults and optimization techniques, culminating in a rigorous comparative analysis of model performance against established benchmarks. By synthesizing the latest research, this guide aims to equip scientists with the knowledge to enhance accuracy and efficiency in binding site prediction, ultimately accelerating drug discovery pipelines.
The Transformative Power of Attention in Computational Biology
An attention mechanism is a machine learning technique that directs deep learning models to prioritize (or attend to) the most relevant parts of input data [1]. Inspired by human cognitive processes, it enables models to selectively focus on salient information while ignoring less relevant details, thereby making efficient use of limited computational resources [1] [2]. This approach has revolutionized artificial intelligence, enabling the transformer architecture that powers modern large language models and has since permeated diverse domains, including structural biology and drug discovery [1] [3].
The mathematical foundation of attention involves computing attention weights that reflect the relative importance of different elements in input data [1]. These weights are typically calculated through a process that determines similarities, correlations, and dependencies between elements, quantified as alignment scores [1]. The scores are normalized via a softmax function to create a probability distribution, which then emphasizes or de-emphasizes the influence of specific input elements on model predictions [1].
Table 1: Key Properties of Attention Mechanisms
| Property | Description | Biological Analogy |
|---|---|---|
| Dynamic Weighting | Adjusts influence of input elements based on context | Selective auditory or visual attention |
| Content-based Addressing | Focuses on elements relevant to current processing step | Contextual prioritization in sensory processing |
| Parallel Processing | Enables simultaneous evaluation of all input elements | Parallel processing in visual cortex |
| Adaptive Focus | Adjusts focus throughout computational process | Task-dependent attention shifting |
Historical Development and Core Concepts
Attention mechanisms were originally introduced by Bahdanau et al. in 2014 to address limitations in sequence-to-sequence (Seq2Seq) models for machine translation [1] [4]. Early Seq2Seq models relied on recurrent neural networks (RNNs) with encoder-decoder architectures, where the encoder processed input sequences into a fixed-length context vector that often became an information bottleneck, particularly for longer sequences [1] [4].
The key innovation was enabling the decoder to access all encoder hidden states, with attention determining which states were most relevant at each decoding step [1]. This fundamental approach has since evolved into several specialized variants, each with distinct computational characteristics and applications.
Critical Technical Differentiation
The original Bahdanau attention and subsequent Luong attention differ primarily in their computational approaches [4]. Bahdanau-style attention uses the previous decoder hidden state to compute attention weights before generating the current state, making attention an integral part of the decoding process [4]. In contrast, Luong-style attention first computes the decoder hidden state and then applies attention to create a context vector that modifies this state before final output generation [4]. This architectural difference enables greater flexibility in experimenting with different attention scoring functions.
Table 2: Major Attention Mechanism Variants and Their Characteristics
| Mechanism Type | Key Innovation | Computational Approach | Primary Applications |
|---|---|---|---|
| Additive Attention (Bahdanau) | First attention mechanism for NMT | Single-layer feedforward network computes alignment | Machine translation, sequence modeling |
| Multiplicative Attention (Luong) | Efficient dot-product operations | Dot product, general, or location-based scoring | Machine translation, text generation |
| Self-Attention | Captures intra-sequence dependencies | Relates different positions of a single sequence | Transformer models, representation learning |
| Cross-Attention | Models relationships between different modalities | Attention between two distinct sequences or data types | Multi-modal learning, protein-ligand interaction |
Attention in Natural Language Processing
In natural language processing, attention mechanisms have largely supplanted earlier encoder-decoder architectures that relied on fixed-length context vectors [2] [4]. The limitations of these earlier approaches were particularly evident for longer sequences, where critical information from early in the sequence tended to be "forgotten" after processing subsequent elements [4].
Self-attention, also called intra-attention, enables models to focus on different positions of the input text sequence to compute a representation of the same sequence [2]. This allows each element to be evaluated in context with all other elements, capturing long-range dependencies that challenge recurrent models [1] [3]. The transformer architecture's multi-head attention mechanism extends this concept by employing multiple attention heads in parallel, each learning to attend to different aspects of the input representation [2].
Diagram 1: NLP Attention Workflow - Core computational steps in transformer-based attention mechanisms for natural language processing.
Attention Mechanisms in Structural Biology
The application of attention mechanisms has extended significantly beyond NLP to address complex challenges in structural biology, particularly in protein-ligand binding site identification and essential protein prediction [5] [6]. These applications leverage attention's ability to integrate diverse biological data sources and identify complex, non-linear relationships within structural and sequential data.
Protein-Ligand Binding Site Prediction with LABind
The LABind method exemplifies advanced attention application for predicting protein binding sites for small molecules and ions in a ligand-aware manner [6]. This approach addresses critical limitations of earlier methods that either treated all ligands identically or required specialized models for specific ligand types [6]. LABind utilizes a graph transformer to capture binding patterns within the local spatial context of proteins and incorporates a cross-attention mechanism to learn distinct binding characteristics between proteins and ligands [6].
The architecture processes ligand information via Simplified Molecular Input Line Entry System (SMILES) sequences through molecular pre-trained language models (MolFormer) to obtain ligand representations [6]. Simultaneously, protein sequences and structures are processed through protein language models (Ankh) and structural analysis tools (DSSP) to generate comprehensive protein representations [6]. The cross-attention mechanism then learns interactions between these representations, enabling accurate binding site prediction even for ligands not encountered during training [6].
Essential Protein Prediction with AttentionEP
AttentionEP demonstrates another significant biological application of attention mechanisms, predicting essential proteins via fusion of multi-scale biological data [5]. This approach integrates protein-protein interaction (PPI) networks, gene expression data, and subcellular localization information using both cross-attention and self-attention frameworks [5].
The method employs Graph Convolutional Networks (GCN) and Graph Attention Networks (GAT) to extract spatial characteristics from PPI networks, Bidirectional Long Short-Term Memory networks (BiLSTM) to derive temporal features from gene expression data, and Deep Neural Networks (DNN) to process subcellular localization information [5]. Self-attention refines features within each data domain, while cross-attention enhances interaction between diverse information sources [5]. This integrated approach achieved an impressive Area Under the Curve (AUC) value of 0.9433, demonstrating considerable advantage over established techniques [5].
Table 3: Performance Comparison of Biological Attention Models
| Model | Primary Task | Key Data Sources | Performance Metrics |
|---|---|---|---|
| LABind [6] | Protein-ligand binding site prediction | Protein structures, ligand SMILES sequences | Superior AUC, AUPR on benchmark datasets DS1, DS2, DS3 |
| AttentionEP [5] | Essential protein prediction | PPI networks, gene expression, subcellular localization | AUC: 0.9433 |
| EGP Hybrid-ML [7] | Essential gene prediction | Gene sequences, multidimensional features | Sensitivity: 0.9122, ACC: ~0.9 |
| DeepEP [5] | Essential protein prediction | PPI networks (node2vec features) | Baseline comparison for AttentionEP |
Experimental Protocols and Methodologies
Computational Protocol for Binding Site Prediction
The LABind methodology provides a comprehensive protocol for structure-based prediction of ligand binding sites [6]:
Input Preparation:
- Ligand Representation: Input SMILES sequence of ligand into MolFormer pre-trained model to obtain molecular representation [6].
- Protein Representation: Process protein sequence and structure through Ankh pre-trained model and DSSP to generate protein embeddings and structural features [6].
- Feature Concatenation: Combine protein embeddings and DSSP features to form protein-DSSP embedding [6].
Graph Construction:
- Convert protein structure into graph representation where nodes represent residues and edges represent spatial relationships [6].
- Derive node spatial features (angles, distances, directions) from atomic coordinates [6].
- Compute edge spatial features (directions, rotations, distances between residues) [6].
- Integrate protein-DSSP embedding with node spatial features to create final protein representation [6].
Attention-Based Learning:
Prediction and Validation:
Diagram 2: Binding Site Prediction Protocol - Experimental workflow for LABind methodology predicting protein-ligand binding sites.
Experimental Protocol for Binding Site Identification via Photoaffinity Labeling
Complementary computational approaches, experimental methods like photoaffinity labeling provide empirical validation of binding sites [8]. The following protocol details experimental identification of binding sites for ivacaftor (VX-770) on the CFTR chloride channel:
Probe Preparation and Validation:
Membrane Preparation:
Photo-labeling Reaction:
Sample Processing and Analysis:
The Scientist's Toolkit: Research Reagent Solutions
Table 4: Essential Research Reagents and Computational Tools for Attention-Based Binding Site Research
| Resource Category | Specific Tools/Reagents | Function/Purpose | Application Context |
|---|---|---|---|
| Pre-trained Models | MolFormer [6], Ankh [6] | Generate molecular and protein representations | Feature extraction for ligand-aware binding site prediction |
| Structural Analysis | DSSP [6], ESMFold [6] | Derive protein structural features | Graph construction from protein 3D structures |
| Experimental Probes | VX-770-Biot, VX-770-Diaz [8] | Covalent labeling of binding sites | Photoaffinity labeling for experimental validation |
| Cell Lines | HEK293 cells [8] | Heterologous protein expression | Production of target proteins for experimental studies |
| Affinity Reagents | Monomeric Avidin Agarose [8] | Enrichment of biotinylated peptides | Isolation of labeled peptides in mass spectrometry |
| Proteolytic Enzymes | Sequence-grade trypsin [8] | Protein digestion | Peptide generation for mass spectrometry analysis |
| Analysis Software | Custom implementations [5] [6] | Model training and prediction | Implementation of attention mechanisms for specific biological tasks |
Integration for Binding Site Identification Research
The integration of computational and experimental approaches provides a powerful framework for binding site identification research. Computational models like LABind generate testable hypotheses about potential binding sites, while experimental methods like photoaffinity labeling provide empirical validation [6] [8]. This synergistic approach accelerates drug discovery by prioritizing candidate interactions for experimental verification.
Cross-attention mechanisms are particularly valuable in this context, as they enable explicit modeling of relationships between protein and ligand representations [6]. This ligand-aware approach represents a significant advancement over methods that treat all ligands identically or require specialized models for specific ligand classes [6]. The ability to predict binding sites for previously unseen ligands demonstrates the generalization capability of these approaches [6].
As attention mechanisms continue to evolve, their application to structural biology promises to unlock deeper insights into protein function, interaction networks, and therapeutic opportunities. The fusion of biological domain knowledge with advanced computational architectures represents a frontier in computational biology with profound implications for understanding fundamental life processes and developing novel therapeutic interventions.
The Query, Key, and Value (QKV) paradigm, central to the attention mechanism in transformer models, provides a powerful computational framework for modeling biological interactions. In the context of binding site identification, this model elegantly formalizes the process of how a protein (or a specific residue within it) "searches" for and interacts with potential binding partners, such as small molecules, ions, or other biomacromolecules. The core analogy is that of a search query looking for matching keys to retrieve relevant values. Here, the Query represents the entity seeking interaction, the Key represents the potential partners that can be matched against, and the Value carries the specific information to be exchanged upon a successful match. Implementing this attention-based framework allows researchers to move beyond static structural analysis to model the dynamic and context-dependent nature of molecular recognition, significantly accelerating the process of drug discovery and functional annotation [6] [9].
Core Conceptual Framework
The QKV Triad: A Biological Analogy
In molecular interaction studies, the QKV model can be mapped onto protein-ligand binding as follows:
- Query (Q): In a ligand-aware binding site prediction, the query often originates from the protein's residues. Each residue, represented by a feature vector derived from its sequence and structural context, acts as a query seeking a binding partner. It asks, "Which ligands or ligand features are relevant to me?" [6] [10].
- Key (K): The keys are derived from the ligand's representation. For a small molecule, this could be a feature vector encoded from its Simplified Molecular Input Line Entry System (SMILES) string or its structure. The keys represent the ligand's identity and properties, ready to be matched against the protein's queries [6].
- Value (V): The values are also derived from the ligand, but they contain the specific information to be propagated to the protein if a match occurs. While keys determine the relevance, values carry the actionable information about the ligand's binding characteristics that influence the final prediction, such as the probability of a residue being a binding site [6] [9].
The attention mechanism computes a compatibility score (e.g., dot product) between each Query and Key pair. This score is then used to compute a weighted sum of all Values, where the weights are determined by the scores. In practice, this means a protein residue will attend most strongly to ligands (or ligand features) whose Keys are most similar to its Query, and the final contextualized representation for the residue will be a blend of the Values from all ligands, weighted by their respective relevance [9].
The Role of Cross-Attention
For predicting binding sites in a ligand-aware manner, cross-attention is the critical mechanism that facilitates the interaction between the two distinct entities: the protein and the ligand. Unlike self-attention where Q, K, and V come from the same source, cross-attention allows the model to learn the distinct binding characteristics between proteins and ligands by using one modality to query the other [6] [10].
In the LABind method, for instance, a graph transformer captures the protein's structural context, generating protein representations. Simultaneously, a molecular language model (MolFormer) processes the ligand's SMILES string to generate the ligand representation. A cross-attention mechanism is then employed where the protein representation acts as the Query, and the ligand representation provides both the Keys and Values. This allows each protein residue to selectively attend to the most relevant aspects of the ligand, effectively learning the interaction patterns that lead to binding [6]. This ligand-aware approach enables the model to generalize and predict binding sites even for ligands not seen during training.
Quantitative Performance of QKV-Based Methods
Advanced deep learning frameworks that implement the QKV and cross-attention paradigm have demonstrated state-of-the-art performance in various binding prediction tasks. The following table summarizes the performance of several key methods on standard benchmark datasets.
Table 1: Performance of MM-IDTarget on Drug-Target Interaction Prediction (Top-K Accuracy, %)
| Method | Top-1 (%) | Top-3 (%) | Top-5 (%) | Top-7 (%) | Top-10 (%) |
|---|---|---|---|---|---|
| MM-IDTarget | 34.68 | 55.88 | 62.31 | 64.00 | 66.07 |
| HitPickV2 | 24.69 | 56.74 | 58.43 | 60.82 | 62.20 |
| SwissTargetPrediction | 28.00 | – | – | – | – |
| Chemogenomic-Model | 26.96 | 56.36 | 59.33 | 60.89 | 63.99 |
The MM-IDTarget framework, which employs intra- and inter-cross-attention mechanisms to fuse multimodal features of drugs and targets, shows superior performance across most Top-K metrics despite being trained on a smaller dataset. This underscores the efficiency of its attention-based feature fusion for target identification [10].
Table 2: Evaluation Metrics for LABind in Binding Site Prediction
| Metric | Full Name | Role in Evaluating QKV-based Binding Site Prediction |
|---|---|---|
| AUPR | Area Under the Precision-Recall Curve | Primary metric for hyperparameter optimization due to robustness to class imbalance [6]. |
| MCC | Matthews Correlation Coefficient | Reflects model performance on imbalanced two-class classification of binding sites [6]. |
| AUC | Area Under the ROC Curve | Measures overall ranking performance of residue binding probabilities [6]. |
| DCC | Distance between predicted and true binding site Centers | Evaluates accuracy in locating the geometric center of a binding pocket [6]. |
Experimental Protocols for QKV Implementation
Protocol 1: Ligand-Aware Binding Site Prediction with LABind
Application Note: This protocol details the steps for implementing the LABind method to predict protein binding sites for specific small molecules or ions, leveraging a cross-attention mechanism between protein and ligand representations [6].
Materials:
- Input Data: Protein sequence and 3D structure (experimental or predicted); Ligand SMILES string.
- Software: LABind framework (requires Python, PyTorch/TensorFlow, graph neural network libraries).
- Pre-trained Models: Ankh (protein language model); MolFormer (molecular language model).
Procedure:
- Input Representation:
- Protein: Generate residue-level embeddings from the protein sequence using the Ankh protein language model. Compute structural features (e.g., solvent accessibility, secondary structure) using DSSP. Combine embeddings and structural features into a final protein representation [6].
- Ligand: Input the ligand's SMILES string into the MolFormer model to obtain a comprehensive molecular representation [6].
- Graph Construction: Convert the protein 3D structure into a graph where nodes represent residues. Node features include spatial information (angles, distances, directions) combined with the protein-DSSP embedding. Edges represent spatial relationships between residues [6].
- Feature Encoding: Process the protein graph through a graph transformer to capture local and global structural contexts. The ligand representation is processed independently [6].
- Cross-Attention Mechanism (QKV Interaction):
- Designate the processed protein residue features as the Query (Q).
- Designate the processed ligand features as the Key (K) and Value (V).
- Compute attention scores:
Attention Scores = Softmax(Q * K^T / sqrt(d)), wheredis the dimensionality of the query and key vectors. - The output for each protein residue is a weighted sum of the ligand Values:
Output = Attention Scores * V[6].
- Binding Site Prediction: Pass the output of the cross-attention layer through a Multi-Layer Perceptron (MLP) classifier to predict a probability for each residue being part of a binding site for the specified ligand [6].
- Validation: Evaluate predictions on benchmark datasets (e.g., DS1, DS2, DS3) using AUPR, MCC, and DCC metrics to assess residue-level and center-level accuracy [6].
Protocol 2: Multimodal Fusion for Drug-Target Interaction with MM-IDTarget
Application Note: This protocol describes an ensemble approach using intra- and inter-cross-attention to fuse sequence and structure modalities of drugs and targets for identifying drug-target interactions (DTI) and ranking potential targets [10].
Materials:
- Input Data: Drug SMILES strings; Target protein sequences and 3D structures.
- Software: MM-IDTarget framework.
- Feature Extractors: Graph Transformer (for drug structures); Multi-Scale CNN (for protein sequences); Residual Edge-Weighted Graph Convolutional Network (for protein structures).
Procedure:
- Feature Extraction:
- Drug Features: Extract structural features from the drug's molecular graph using a Graph Transformer. Extract sequence features from the SMILES string using a Multi-Scale CNN (MCNN) [10].
- Target Features: Extract sequence features from the protein sequence using an MCNN. Extract structural features from the protein structure using a Residual Edge-Weighted GCN (EW-GCN) [10].
- Intra-Cross-Attention (Within-Modality Fusion):
- For both the drug and the target, independently fuse their own sequence and structural features.
- Use a cross-attention block where, for example, the sequence features act as the Query and the structural features act as the Key and Value (or vice-versa). This allows the model to emphasize the most salient complementary information from different modalities of the same entity [10].
- Inter-Cross-Attention (Between-Entity Fusion):
- Fuse the enriched drug and target representations. Let the fused drug representation be the Query and the fused target representation be the Key and Value (or vice-versa).
- This step allows the drug to query the target database, learning complex interaction patterns between them [10].
- Prediction and Ranking:
- Combine the output of the inter-cross-attention with physicochemical features of the drug and target.
- Use a fully connected network to predict interaction scores (for DTI) or binding affinity (for DTA).
- For target identification, rank all potential targets for a given drug in descending order of their predicted scores (Top-K ranking) [10].
Diagram 1: Workflow of ligand-aware binding site prediction using QKV cross-attention, as implemented in methods like LABind.
Table 3: Key Computational Tools for QKV-Based Binding Site Research
| Tool Name | Type | Primary Function in QKV Context |
|---|---|---|
| Ankh | Protein Language Model | Generates powerful sequence-based residue embeddings used to form the Query in protein-ligand attention [6]. |
| MolFormer | Molecular Language Model | Generates ligand representations from SMILES strings, providing the Keys and Values for cross-attention [6]. |
| ESM-2 | Protein Language Model | Used in other frameworks (e.g., ESM-SECP) to extract residue embeddings from protein sequences [11]. |
| Graph Transformer | Deep Learning Architecture | Encodes the protein's 3D structural graph, capturing local spatial contexts for residues [6] [10]. |
| 3D U-Net with Attention | Deep Learning Architecture | Used for semantic segmentation of 3D protein structures to predict binding pockets, employing attention to focus on salient spatial and channel features [12]. |
| DSSP | Bioinformatics Tool | Computes secondary structure and solvent accessibility from protein 3D coordinates, enriching node features in protein graphs [6]. |
Diagram 2: Multimodal fusion framework using intra- and inter-cross-attention for drug-target interaction prediction, as seen in MM-IDTarget.
The identification of molecular binding sites is a cornerstone of modern drug discovery and functional genomics. Traditional computational methods, which often rely on manually curated features and static structural models, are increasingly constrained by their limited adaptability and "black-box" nature. The integration of attention mechanisms into deep learning architectures is fundamentally reshaping this landscape. These mechanisms provide a powerful, native capacity for data-driven feature learning and unprecedented model interpretability, offering researchers a clear view into the decision-making processes of complex models. This application note details how these advantages are being practically implemented to accelerate and refine binding site identification research.
Quantitative Advantages of Attention-Based Models
The theoretical benefits of attention mechanisms translate into superior quantitative performance across various prediction tasks. The table below summarizes benchmark results from recent state-of-the-art studies.
Table 1: Performance Benchmarks of Advanced Binding Site Prediction Models
| Model Name | Prediction Focus | Key Architecture | Performance Metrics | Traditional Method Comparison |
|---|---|---|---|---|
| GHCDTI [13] | Drug-Target Interaction (DTI) | Graph Wavelet Transform + Multi-level Contrastive Learning | AUC: 0.966 ± 0.016, AUPR: 0.888 ± 0.018 | Significantly outperforms methods neglecting protein dynamics and data imbalance. |
| LABind [6] | Protein-Ligand Binding Sites | Graph Transformer + Cross-Attention | Superior Rec, Pre, F1, MCC, AUC, and AUPR on multiple benchmark datasets (DS1, DS2, DS3). | Outperforms single-ligand and multi-ligand oriented methods, generalizing to unseen ligands. |
| PreRBP [14] | RNA-Protein Binding Sites | CNN-BiLSTM-Attention | Average AUC: 0.88 | Higher accuracy than existing RNA-protein binding site prediction methods. |
| PFDCNN [15] | Protein-ATP Binding Sites | Protein LLM (ESM) + Fractional-Order CNN | Accuracy: 0.984, AUC: 0.941 | Surpasses most existing predictors like ATPint, ATPsite, and TargetATPsite. |
| TBiNet [16] | Transcription Factor Binding Sites | Attention-based DNN | Outperforms DeepSea and DanQ. | More effective in discovering known TF-binding motifs. |
Experimental Protocols for Attention-Based Binding Site Prediction
Protocol 1: Structure-Based Prediction with Cross-Attention (LABind)
This protocol is designed for predicting protein binding sites for small molecules and ions in a ligand-aware manner, even for unseen ligands [6].
Input Representation:
- Ligand: Encode the ligand's SMILES sequence into a molecular representation vector using a pre-trained molecular language model (e.g., MolFormer).
- Protein: For a protein structure, generate a residue-level graph where nodes represent amino acids and edges represent spatial relationships.
- Node Features: Combine sequence embeddings from a protein language model (e.g., Ankh) with structural features (e.g., angles, distances, directions) derived from atomic coordinates.
- Edge Features: Encode spatial relationships between residues, including directions, rotations, and distances.
Model Architecture & Training:
- Graph Transformer: Process the protein graph to capture potential binding patterns in the local spatial context.
- Cross-Attention Module: Fuse the protein and ligand representations. This mechanism allows the protein residues to "attend" to the ligand representation, learning distinct binding characteristics for the specific ligand.
- Classifier: Pass the final integrated representations through a Multi-Layer Perceptron (MLP) to predict a binding probability for each residue.
- Handling Data Imbalance: Use metrics like Matthews Correlation Coefficient (MCC) and Area Under the Precision-Recall Curve (AUPR) for evaluation and hyperparameter tuning, as they are more reliable for imbalanced data.
Output & Interpretation:
- The model outputs a binding probability for each residue in the protein sequence.
- Interpretability: The cross-attention weights can be visualized to identify which parts of the protein sequence and which aspects of the ligand representation were most critical for the prediction, providing residue-level insights into the binding interaction.
Protocol 2: Sequence-Based Prediction with Integrated Attention (PreRBP)
This protocol predicts binding sites using primarily sequence data, effectively handling long-range dependencies and class imbalance [14].
Input & Feature Engineering:
- RNA Sequence: Encode sequences using higher-order encoding algorithms to extract key information.
- Structural Context: Predict RNA secondary structure using tools like RNAshapes to incorporate structural features beyond the primary sequence.
- Addressing Class Imbalance: Apply undersampling algorithms (e.g., Random Undersampling, NearMiss, ENN, One-Sided Selection) to the negative samples in the training dataset to construct a balanced training set.
Model Architecture & Training:
- Feature Learning Backbone: Employ a Convolutional Neural Network (CNN) to detect local motif-level patterns, followed by a Bidirectional Long Short-Term Memory network (BiLSTM) to capture long-range, global contextual information in the sequence.
- Attention Layer: Integrate an attention mechanism on top of the BiLSTM outputs. This layer assigns a weight to each position in the sequence, allowing the model to focus on the most critical regions for binding.
- Output Layer: Use a fully connected layer with a softmax activation for final classification (binding vs. non-binding site).
Output & Interpretation:
- The model outputs a binding site prediction.
- Interpretability: The attention weights produced by the model can be plotted as a graph over the input sequence, directly highlighting the specific nucleotide regions (e.g., potential motifs) that most strongly influenced the binding site prediction.
The Scientist's Toolkit: Research Reagent Solutions
Table 2: Essential Resources for Attention-Based Binding Site Research
| Category | Reagent / Resource | Function & Application | Example Tools / Datasets |
|---|---|---|---|
| Computational Frameworks | Graph Neural Network Libraries | Facilitate the building of GATs and Graph Transformers for structure-based models. | PyTorch Geometric, Deep Graph Library (DGL) |
| Transformer Libraries | Provide pre-built modules for multi-head self-attention and transformer architectures. | Hugging Face Transformers, TensorFlow | |
| Data Resources | Protein-Ligand Binding Data | Benchmark datasets for training and evaluating structure-based binding site predictors. | sc-PDB, COACH420, HOLO4k, PDBBind [17] |
| Protein-Sequence Databases | Large-scale sequence databases for training protein Language Models (pLMs). | UniRef50, UniRef90 [15] | |
| RNA-Protein Interaction Data | Sources of experimentally derived data for training RNA-protein binding site models. | iCount, DoRiNA [14] | |
| Pre-trained Models | Protein Language Models (pLMs) | Generate rich, contextual embeddings from protein sequences, capturing evolutionary and structural information. | ESM-1b, ESM-2, ProtTrans, ProtBert [17] [15] |
| Molecular Language Models | Encode small molecules (via SMILES) into meaningful representation vectors for ligand-aware prediction. | MolFormer [6] | |
| Analysis & Visualization | Molecular Visualization Software | Visualize 3D protein structures and map predicted binding sites onto them for validation. | PyMol [17] |
| Metric Libraries | Compute advanced metrics crucial for evaluating model performance on imbalanced datasets. | Scikit-learn (for MCC, AUPR) |
The integration of attention mechanisms represents a paradigm shift from rigid, traditional computational methods to adaptive, interpretable, and data-driven AI tools. As demonstrated by protocols like LABind and PreRBP, these models do not merely offer a performance boost; they provide a collaborative framework where the model's reasoning is exposed to the scientist. This enhanced interpretability, coupled with the ability to learn directly from complex and heterogeneous data, is empowering researchers to make more informed decisions, rapidly validate hypotheses, and ultimately accelerate the pace of discovery in structural biology and drug development.
The accurate identification of molecular binding sites is a fundamental challenge in modern drug discovery and bioinformatics. Attention mechanisms have emerged as powerful deep learning components that enable models to focus on the most relevant parts of complex biological data, significantly advancing binding site prediction. These architectures—self-attention, graph attention networks (GATs), and cross-attention—provide distinct approaches for processing sequential, structural, and interaction data between biomolecules. By learning context-aware relationships within and between biological entities, attention-based models have demonstrated superior performance over traditional computational methods while offering valuable interpretability insights into the molecular determinants of binding interactions [18] [19].
Self-attention mechanisms allow models to weigh the importance of different positions within a single sequence or structure, capturing long-range dependencies that are critical for understanding biomolecular function. Graph attention networks specialize in processing graph-structured data by applying attention to node neighborhoods, making them ideally suited for analyzing protein structures and molecular graphs. Cross-attention mechanisms enable interactive learning between different molecular representations, such as between drug compounds and their protein targets, allowing the model to jointly reason over both entities when predicting binding interactions [20] [21]. Together, these architectures form a powerful toolkit for addressing the complex challenge of binding site identification across diverse biological contexts.
Architectural Foundations and Theoretical Frameworks
Self-Attention Mechanism
The self-attention mechanism, also known as intra-attention, computes representation of a sequence by weighing the importance of all other elements in the same sequence when encoding each position. For a given input matrix X containing n elements (e.g., amino acids in a protein sequence), the self-attention operation transforms it into query (Q), key (K), and value (V) matrices through linear projections. The attention weights are computed as:
Attention(Q, K, V) = softmax(QKᵀ/√dₖ)V
where dₖ is the dimension of the key vectors, and the softmax function normalizes the weights across the sequence [22]. The scaling factor √dₖ prevents the softmax function from entering regions with extremely small gradients. This mechanism allows each position in the sequence to attend to all other positions, capturing global dependencies regardless of their distance in the sequence.
In binding site identification, self-attention enables models to identify functionally important residues that may be distributed throughout the protein sequence but collectively contribute to binding site formation. For example, SAResNet combines self-attention with residual networks to predict DNA-protein binding sites, where the self-attention module captures position information of DNA sequences while the residual structure extracts high-level features of binding sites [22]. The multi-headed extension of self-attention allows the model to jointly attend to information from different representation subspaces, capturing different types of relationships within the biological sequence.
Graph Attention Networks (GATs)
Graph Attention Networks represent a specialized architecture for processing graph-structured data, which naturally represents many biological systems including protein structures and molecular graphs. In GATs, each node in the graph computes its updated representation by attending to its neighbors, allowing for focused integration of local structural information [23].
The graph attention layer employs a shared attention mechanism a that computes attention coefficients between node pairs:
eᵢⱼ = a(Whᵢ, Whⱼ)
where hᵢ and hⱼ are node features, W is a shared weight matrix, and eᵢⱼ indicates the importance of node j's features to node i [23]. These coefficients are normalized across all neighbors j ∈ Nᵢ using the softmax function, and the resulting attention weights are used to compute a weighted average of neighbor transformations. The GATv2 architecture improves upon this by using a more expressive attention function:
αᵢ,ⱼ = exp(aᵀLeakyReLU(Θ[xᵢ||xⱼ||eᵢ,ⱼ])) / Σₖ∈Nᵢ∪{i} exp(aᵀLeakyReLU(Θ[xᵢ||xₖ||eᵢ,ₖ]))
where || represents concatenation, Θ and a are learned parameters, and eᵢ,ⱼ are edge features [23]. This formulation allows for more flexible and powerful attention patterns in biological graphs.
For binding site prediction, GATs excel at capturing the local chemical environment around potential binding residues by representing protein structures as graphs where nodes correspond to atoms or residues and edges represent spatial proximity or chemical bonds. The GrASP model demonstrates this approach by performing semantic segmentation on protein surface atoms using GATs to identify which atoms are likely part of a binding site [23].
Cross-Attention Mechanism
Cross-attention mechanisms enable information exchange between two different sequences or representations, making them particularly valuable for modeling interactions between distinct biological entities such as drug-target pairs or enzyme-substrate complexes. Unlike self-attention, which operates within a single sequence, cross-attention computes attention weights between elements from two different domains [20] [21].
In cross-attention, the queries (Q) come from one sequence while the keys (K) and values (V) come from another. For drug-target interaction prediction, this allows the model to compute attention from drug subsequences to protein subsequences or vice versa:
CrossAttention(Qₚ, K₄, V₄) = softmax(QₚK₄ᵀ/√dₖ)V₄
where Qₚ are queries from protein sequences and K₄, V₄ are keys and values from drug representations [21]. This mechanism enables the model to identify which drug substructures are most relevant to which protein regions, and which protein residues are most influenced by specific drug components.
The ICAN model exemplifies this approach for drug-target interaction prediction, where cross-attention generates drug-related context features for proteins and protein-related context features for drugs [20] [21]. Similarly, LABind employs cross-attention to learn distinct binding characteristics between proteins and ligands by processing protein representations and ligand representations through attention-based learning interaction modules [6]. EZSpecificity utilizes cross-attention empowered SE(3)-equivariant graph neural networks to predict enzyme substrate specificity by capturing interactions between enzyme structures and substrate representations [24].
Performance Comparison of Attention Architectures
Table 1: Quantitative performance of attention-based architectures on various binding site prediction tasks
| Architecture | Model Name | Application Domain | Performance Metrics | Key Advantage |
|---|---|---|---|---|
| Self-Attention | SAResNet | DNA-protein binding prediction | Average AUC: 92.0% on 690 ChIP-seq datasets [22] | Captures long-range dependencies in sequences |
| Graph Attention | GrASP | Druggable binding site prediction | >70% of predicted sites correspond to real binding sites [23] | Rotationally invariant featurization of protein surfaces |
| Cross-Attention | ICAN | Drug-target interaction identification | Outperformed state-of-the-art methods on DAVIS dataset [20] [21] | Identifies interacting subsequences between drugs and proteins |
| Cross-Attention | LABind | Protein-ligand binding sites | Superior performance on DS1, DS2, and DS3 benchmark datasets [6] | Ligand-aware prediction for unseen ligands |
| Cross-Attention | EZSpecificity | Enzyme substrate specificity | 91.7% accuracy identifying single potential reactive substrate [24] | Captures 3D structural determinants of enzyme specificity |
Table 2: Input representations and dataset characteristics for attention-based binding site prediction
| Model | Protein Representation | Ligand/DNA Representation | Dataset Characteristics | Training Strategy |
|---|---|---|---|---|
| SAResNet | One-hot encoded DNA sequences (101-bp) | N/A | 690 ChIP-seq datasets; 4,614,580 training sequences [22] | Transfer learning with pre-training and fine-tuning |
| ICAN | Amino acid sequences | SMILES strings | DAVIS: 68 drugs, 379 proteins; BindingDB: 10,665 drugs, 1,413 proteins [20] [21] | Cross-attention with CNN decoder |
| LABind | Sequence (Ankh PLM) + structure (DSSP) | SMILES (MolFormer PLM) | DS1, DS2, DS3 benchmarks; focuses on small molecules and ions [6] | Graph transformer with cross-attention |
| GrASP | Protein structure graphs (heavy atoms) | N/A | 26,196 binding sites across 16,889 protein structures [23] | GAT-based semantic segmentation on surface atoms |
| CAFIE-DTA | Sequence + 3D curvature + electrostatic potential | Molecular graph + physicochemical properties | Davis and KIBA datasets [25] | Multi-head cross-attention fusion |
Experimental Protocols for Binding Site Identification
Protocol 1: DNA-Protein Binding Site Prediction with Self-Attention
Application Note: This protocol describes the implementation of self-attention mechanisms for predicting DNA-protein binding sites using the SAResNet framework, which combines self-attention with residual network structures [22].
Materials and Reagents:
- Computational Environment: High-performance computing cluster with GPU acceleration
- Software Dependencies: Python 3.7+, PyTorch 1.8+, scikit-learn 1.0+
- Dataset: 690 ChIP-seq datasets from ENCODE project
Methodology:
- Data Preprocessing:
- Format DNA sequences as 101-bp length one-hot encoded vectors (4×101 dimensions)
- Combine training subsets from 690 datasets while maintaining independence of testing subsets
- Apply under-sampling strategy to address class imbalance
- Partition data into global training (90%), validation (10%), and testing sets
Model Architecture Configuration:
- Implement residual blocks with bottleneck design (1×1, 3×3, 1×1 convolutions)
- Integrate self-attention module after residual blocks to capture position information
- Configure multi-headed self-attention with 8 attention heads
- Set embedding dimension to 512 with feed-forward dimension of 2048
Training Procedure:
- Initialize model with He normal initialization
- Utilize transfer learning: pre-train on global dataset, then fine-tune on specific datasets
- Employ Adam optimizer with initial learning rate of 0.001
- Implement learning rate scheduling with reduction on plateau
- Train for maximum 200 epochs with early stopping patience of 15 epochs
Performance Validation:
- Evaluate on independent test set using AUC, accuracy, precision, recall, and F1 score
- Compare against state-of-the-art methods (DeepBind, CNN-Zeng, Expectation-Luo)
- Perform statistical significance testing across 690 datasets
Troubleshooting:
- For overfitting on smaller datasets: increase dropout rate (0.3-0.5) and implement stronger L2 regularization
- For slow convergence: adjust learning rate scheduling or switch to LayerNorm instead of BatchNorm
- For memory issues: reduce batch size or implement gradient accumulation
Protocol 2: Ligand-Aware Binding Site Prediction with Cross-Attention
Application Note: This protocol outlines the use of cross-attention mechanisms for predicting protein-ligand binding sites in a ligand-aware manner using the LABind framework, which integrates protein structure information with ligand chemical representations [6].
Materials and Reagents:
- Computational Environment: Linux server with NVIDIA GPU (≥16GB VRAM)
- Software Dependencies: RDKit, PyTorch Geometric, Ankh protein language model, MolFormer
- Dataset: Curated benchmark datasets (DS1, DS2, DS3) with diverse ligands
Methodology:
- Feature Extraction:
- Protein Representation:
- Generate sequence embeddings using Ankh protein language model
- Compute structural features using DSSP (secondary structure, solvent accessibility)
- Construct protein graph from structure with nodes as residues
- Calculate spatial features: angles, distances, directions from atomic coordinates
- Ligand Representation:
- Process SMILES sequences through MolFormer pre-trained model
- Extract molecular features including functional groups, charge distribution
- Protein Representation:
Cross-Attention Integration:
- Implement cross-attention blocks where protein features serve as queries and ligand features as keys/values
- Use multi-head attention with 8 heads and hidden dimension of 512
- Apply residual connections around attention blocks
- Utilize layer normalization before each attention block
Binding Site Prediction:
- Process cross-attention output through multi-layer perceptron classifier
- Apply sigmoid activation for per-residue binding probability
- Use optimal threshold determined by maximizing Matthews correlation coefficient
- Cluster predicted binding residues to identify binding site centers
Evaluation Metrics:
- Calculate recall, precision, F1 score, Matthews correlation coefficient
- Compute area under ROC curve (AUC) and precision-recall curve (AUPR)
- Measure distance between predicted and true binding site centers (DCC, DCA)
Troubleshooting:
- For poor generalization to unseen ligands: increase diversity of training ligands and augment with molecular graph perturbations
- For structural feature extraction errors: validate PDB file formatting and implement coordinate sanity checks
- For attention collapse: monitor attention weight distributions and add entropy regularization
Protocol 3: Druggable Binding Site Prediction with Graph Attention Networks
Application Note: This protocol details the application of graph attention networks for identifying druggable binding sites on protein surfaces using the GrASP framework, which performs semantic segmentation on protein surface atoms [23].
Materials and Reagents:
- Computational Environment: Python 3.8+ with CUDA 11.0+
- Software Dependencies: PyTorch 1.10+, PyTorch Geometric, Biopython, NumPy
- Dataset: sc-PDB database (26,196 binding sites across 16,889 structures)
Methodology:
- Protein Graph Construction:
- Represent protein as graph with nodes corresponding to heavy atoms
- Define edges between atom pairs within 5Å distance
- Node features: atomic number, formal charge, residue type, etc.
- Edge features: inverse distance, bond order, spatial relationships
Graph Attention Network Architecture:
- Implement GATv2 layers with improved attention mechanism
- Configure 4 attention heads with hidden dimension of 256
- Integrate ResNet skip connections to mitigate oversmoothing
- Apply jumping knowledge skip connections to combine multi-scale features
- Utilize Noisy Nodes regularization for improved representation learning
Binding Site Definition and Training:
- Assign continuous target scores to surface atoms using sigmoid function of distance to ligand
- Construct near-surface graph including surface atoms and buried atoms within 5Å
- Train model with weighted binary cross-entropy loss
- Implement gradient clipping with maximum norm of 1.0
Binding Site Clustering and Ranking:
- Aggregate atomic scores into potential binding sites using average linkage clustering
- Rank predicted sites by average atomic scores
- Filter sites by volume and surface accessibility criteria
- Validate against co-crystallized ligand positions
Troubleshooting:
- For oversmoothing in deep GNN: implement pair normalization or increase jumping knowledge connections
- For memory constraints with large proteins: implement subgraph sampling or hierarchical processing
- For false positive binding sites: incorporate evolutionary conservation signals or energetic calculations
Workflow Visualization
Research Reagent Solutions
Table 3: Essential research reagents and computational tools for attention-based binding site identification
| Reagent/Tool | Type | Function | Example Implementation |
|---|---|---|---|
| Ankh Protein Language Model | Pre-trained Model | Generates protein sequence representations | LABind: Provides protein embeddings from sequence [6] |
| MolFormer | Pre-trained Model | Generates molecular representations from SMILES | LABind: Creates ligand embeddings [6] |
| RDKit | Cheminformatics Library | Processes molecular structures and descriptors | ICAN: Handles SMILES validation and molecular features [20] [21] |
| DSSP | Structural Bioinformatics Tool | Computes secondary structure and solvent accessibility | LABind: Extracts protein structural features [6] |
| PyTorch Geometric | Deep Learning Library | Implements graph neural networks | GrASP: Builds protein graph models [23] |
| ChIP-seq Datasets | Experimental Data | Provides DNA-protein binding information | SAResNet: Training and evaluation on 690 datasets [22] |
| sc-PDB Database | Curated Database | Contains annotated binding sites | GrASP: Training on 26,196 binding sites [23] |
| ESMFold | Structure Prediction | Predicts protein structures from sequences | LABind: Enables sequence-based binding site prediction [6] |
Attention mechanisms have fundamentally transformed the computational approaches for binding site identification, offering unprecedented performance and interpretability. Self-attention excels at capturing long-range dependencies in biological sequences, graph attention networks provide natural representations for structural data, and cross-attention enables sophisticated modeling of molecular interactions. The integration of these architectures with advanced representation learning techniques, such as protein language models and molecular graph embeddings, has created a powerful paradigm for deciphering the molecular basis of binding interactions.
Future developments in this field will likely focus on several key directions. Multi-scale attention mechanisms that integrate sequence, structure, and physicochemical information will provide more comprehensive binding site characterization. Equivariant attention networks that respect biological symmetries will improve generalization across diverse molecular configurations. Explainable AI approaches built upon attention weight analysis will deepen our understanding of binding determinants and facilitate scientific discovery. As these architectures continue to evolve, they will play an increasingly central role in accelerating drug discovery and advancing our fundamental understanding of molecular recognition biology.
The Role of Attention in Capturing Protein-Ligand Interaction Patterns
Protein-ligand interactions are fundamental to numerous biological processes, including enzyme catalysis and signal transduction, and are pivotal in drug discovery and design [6]. Accurately identifying these interactions is critical for understanding cellular functions and developing new therapeutics. However, traditional experimental methods for determining binding sites are resource-intensive, creating a pressing need for efficient computational approaches [6].
The attention mechanism, a component of modern artificial intelligence, has recently been adapted to decode the complex "languages" of protein sequences and ligand representations [26]. This mechanism allows models to dynamically focus on the most relevant residues in a protein sequence or atoms in a ligand, significantly improving the prediction of binding sites and interaction patterns [27] [26]. This application note details how attention mechanisms are implemented to capture protein-ligand interaction patterns, providing structured protocols, performance data, and essential toolkits for researchers.
Theoretical Foundations: Attention for Protein and Ligand Representation
Proteins and Ligands as Structured Languages
Proteins and ligands can be represented in text-like formats suitable for NLP methods. Protein sequences consist of a linear chain of amino acids, analogous to an alphabet forming words and sentences [26]. Similarly, the chemical structure of small molecule ligands can be represented as text using the Simplified Molecular-Input Line-Entry System (SMILES), a string notation that captures atoms, bonds, and branching [6] [26].
The Attention Mechanism
The attention mechanism functions like a dynamic filter, enabling computational models to weigh the importance of different input elements [28]. For protein-ligand interactions, this means a model can learn to prioritize specific amino acid residues or ligand functional groups that critically influence binding. A key advancement is the cross-attention mechanism, which explicitly learns the distinct binding characteristics between a protein and a specific ligand by processing their respective representations [6]. This is a fundamental improvement over methods that only consider protein structure in isolation.
Application Note: The LABind Protocol for Ligand-Aware Binding Site Prediction
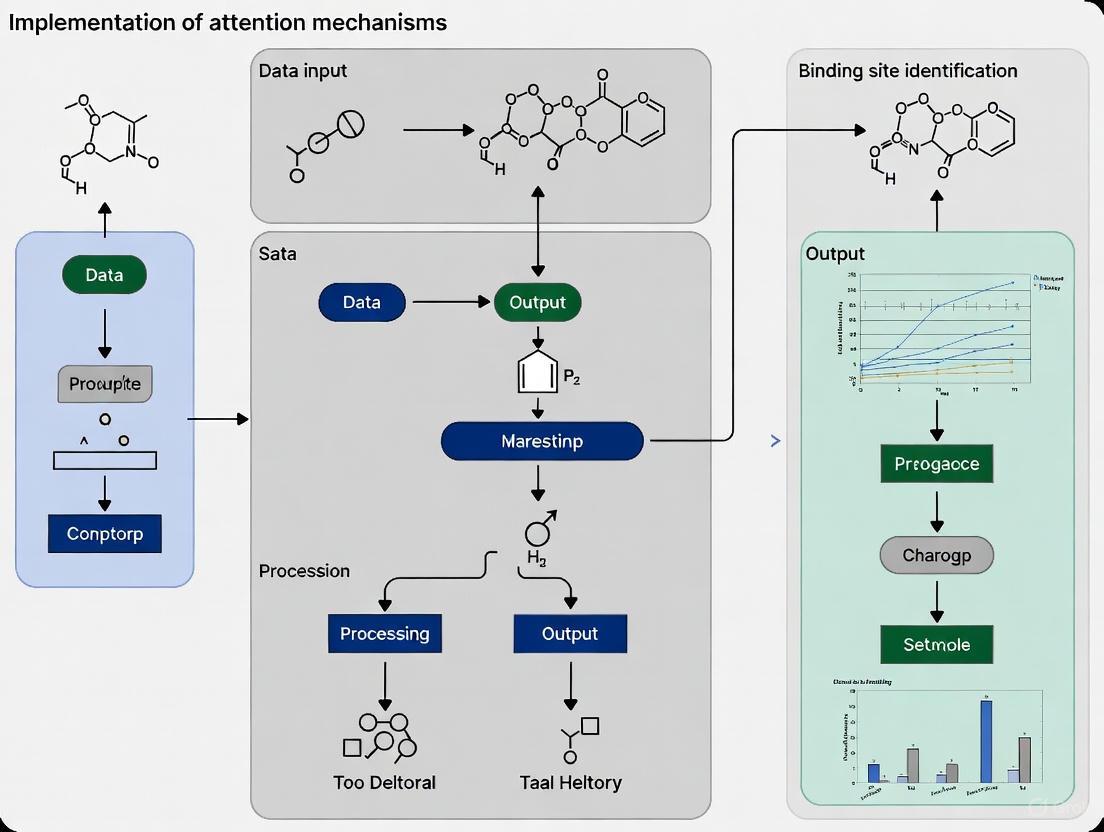
LABind is a structure-based method that leverages a graph transformer and cross-attention mechanism to predict binding sites for small molecules and ions in a ligand-aware manner [6]. Its ability to generalize to unseen ligands makes it a powerful tool for prospective drug discovery.
The following diagram illustrates the end-to-end LABind protocol for predicting protein-ligand binding sites.
Step-by-Step Experimental Protocol
Stage 1: Input Representation and Feature Extraction
Step 1.1: Ligand Representation via SMILES
- Obtain the SMILES string of the target small molecule or ion from databases like PubChem or ZINC.
- Input the SMILES sequence into the MolFormer pre-trained molecular language model to generate a numerical ligand representation vector that encapsulates molecular properties [6].
Step 1.2: Protein Representation via Sequence and Structure
- Sequence Embedding: Input the protein's amino acid sequence into the Ankh pre-trained protein language model to obtain residue-level embeddings [6].
- Structural Feature Extraction: Process the protein's 3D structure (from PDB or predicted by ESMFold/AlphaFold) with DSSP to calculate secondary structure, solvent accessibility, and backbone dihedral angles [6].
- Feature Concatenation: For each residue, concatenate its Ankh embedding with its DSSP features to form a preliminary protein-DSSP embedding.
Step 1.3: Protein Graph Construction
- Convert the protein structure into a graph where nodes represent residues.
- Node Features: Encode the protein-DSSP embedding with spatial features (angles, distances, directions) derived from atomic coordinates.
- Edge Features: Connect residues based on spatial proximity and encode edge features (directions, rotations, inter-residue distances) [6].
Stage 2: Attention-Based Learning Interaction
Step 2.1: Graph Transformation
- Process the protein graph through a graph transformer network. This step captures the potential binding patterns within the local spatial context of the protein by modeling residue-residue interactions [6].
Step 2.2: Cross-Attention Execution
- The processed protein representation and the ligand representation are fed into a cross-attention module.
- This mechanism allows the model to learn the distinct binding characteristics between the specific protein and ligand by enabling the protein residues to "attend to" the most relevant features of the ligand, and vice-versa [6].
Stage 3: Binding Site Prediction and Validation
Step 3.1: Classification
- The output from the cross-attention mechanism is passed to a multi-layer perceptron (MLP) classifier.
- The MLP performs per-residue binary classification, predicting whether each residue is part of a binding site for the specified ligand [6].
Step 3.2: Output and Center Localization
- The final output is a probability map across all protein residues.
- Residues with probabilities above a threshold (determined by maximizing Matthews Correlation Coefficient) are designated as binding site residues.
- For a singular binding site, the predicted residues can be clustered, and their spatial center calculated to localize the binding site center [6].
Step 3.3: Experimental Validation
- Validate computational predictions against known experimental structures from the PDB.
- For novel predictions, confirm binding sites experimentally using techniques like X-ray crystallography, Cryo-EM, or site-directed mutagenesis followed by binding assays [26].
Performance Metrics and Validation
LABind's performance was benchmarked on several datasets against other state-of-the-art methods. The following table summarizes key quantitative results, demonstrating its superiority, particularly in metrics robust to class imbalance.
Table 1: Performance Comparison of LABind Against Baseline Methods on Benchmark Datasets [6]
| Method | Dataset | AUPR | MCC | F1 Score | AUC |
|---|---|---|---|---|---|
| LABind | DS1 | 0.723 | 0.521 | 0.685 | 0.971 |
| DeepPocket | DS1 | 0.621 | 0.432 | 0.601 | 0.945 |
| P2Rank | DS1 | 0.598 | 0.410 | 0.578 | 0.938 |
| LABind | DS2 | 0.685 | 0.488 | 0.642 | 0.962 |
| DeepPocket | DS2 | 0.584 | 0.395 | 0.554 | 0.931 |
| P2Rank | DS2 | 0.562 | 0.378 | 0.537 | 0.925 |
| LABind | DS3 | 0.651 | 0.467 | 0.623 | 0.955 |
| LigBind | DS3 | 0.592 | 0.402 | 0.562 | 0.934 |
| GeoBind | DS3 | 0.535 | 0.351 | 0.512 | 0.917 |
The Scientist's Toolkit: Research Reagent Solutions
Successful implementation of attention-based binding site prediction requires a suite of computational tools and data resources.
Table 2: Essential Research Reagents and Computational Tools
| Item Name | Type | Function in Protocol | Example Sources / Implementations |
|---|---|---|---|
| Pre-trained Language Models | Software | Generate numerical representations from raw sequence data. | Ankh (Protein), MolFormer (Ligand SMILES) [6] |
| Protein Structure Databases | Data | Source of experimentally-solved protein 3D structures for training, testing, and analysis. | Protein Data Bank (PDB) [26] |
| Ligand Databases | Data | Source of small molecule structures and properties. | PubChem, ZINC, ChEMBL |
| Bioactivity Datasets | Data | Provide ground-truth interaction data for model training and validation. | PDBBind, DUD-E, Davis, KIBA [26] |
| Structure Prediction Tools | Software | Generate 3D protein structures from sequence when experimental structures are unavailable. | ESMFold, AlphaFold2 [6] [27] |
| Structure Analysis Tools | Software | Extract key structural features from protein 3D coordinates. | DSSP [6] |
| Graph Neural Network Libraries | Software | Build and train graph-based models for processing protein structures. | PyTorch Geometric, Deep Graph Library |
| Molecular Processing Kits | Software | Handle and manipulate small molecule structures and SMILES strings. | RDKit [26] |
Advanced Applications and Integration
Enhancing Molecular Docking
The binding sites predicted by LABind can be used to define search spaces for molecular docking programs like Smina, substantially improving the accuracy of docking poses by restricting sampling to relevant regions [6].
Case Study: SARS-CoV-2 NSP3 Macrodomain
LABind demonstrated practical utility by successfully predicting the binding sites of the SARS-CoV-2 NSP3 macrodomain with unseen ligands, validating its application in real-world drug discovery scenarios against emerging targets [6].
Integration with Other Modalities
Future directions involve tighter integration with other data types. For instance, foundation models are being applied to extract features from histopathology images, which could be layered with molecular interaction data to link tissue-level phenotypes with molecular mechanisms [29]. Furthermore, specialized GPT models like ProtGPT2 and BioGPT are advancing protein engineering and biomedical text mining, creating opportunities for multi-modal predictive systems in drug discovery [30].
Implementing Attention-Based Models for Binding Site Prediction
The accurate encoding of protein structures is a foundational challenge in computational biology, with direct implications for understanding function, guiding drug discovery, and designing novel therapeutics. Traditional methods often struggle to simultaneously capture the intricate local atomic interactions and the long-range, global dependencies that define a protein's functional architecture. The advent of graph transformer networks represents a paradigm shift, offering a powerful framework that models protein structures as graphs and leverages attention mechanisms to overcome these limitations. This document details the application of these architectures within the specific context of a research thesis focused on implementing attention mechanisms for binding site identification. We provide a structured blueprint of the core architecture, summarize quantitative performance, outline detailed experimental protocols, and visualize key workflows to equip researchers with the practical tools needed for implementation.
Core Architectural Principles
Graph transformer models for protein encoding share a common foundational strategy: representing a protein structure as a graph where nodes correspond to atoms or residues, and edges represent their spatial or chemical relationships. The transformative power of these models lies in their use of attention mechanisms to dynamically weigh the importance of interactions within this graph.
- Graph Representation: The initial step involves converting a protein's 3D structure into a graph. Nodes are typically defined by alpha carbon atoms or full residue side chains, featurized with chemical properties, sequence embeddings, or structural descriptors. Edges can be determined based on spatial proximity (e.g., k-nearest neighbors) or chemical bonding, and are often annotated with spatial and rotational information [31] [32].
- Attention with Structural Biases: Unlike standard transformers used in natural language processing, graph transformers for proteins incorporate structural inductive biases directly into the attention mechanism. This is critical for respecting the physical laws of structural biology. For instance, pairwise atomic distances can be converted into continuous or categorical attention biases, ensuring that geometrically closer nodes can interact more strongly [32] [33]. The gated graph transformer used in DProQA, for example, employs node and edge gates within the transformer framework to adaptively control information flow during message passing, enhancing the model's ability to assess the quality of protein complex structures [32].
- Hierarchical and Multi-Scale Modeling: Advanced architectures like SPE-GTN employ a two-branch encoding framework to capture information at multiple scales. A Structure Encoding (SE) branch focuses on local topological features via subgraph sampling, while a Position Encoding (PE) branch captures global functional context within a protein interaction network using Laplacian spectral decomposition. The outputs are fused using a trainable parameter, allowing the model to adaptively balance local and global information [34].
Performance Benchmarking
The following tables summarize the performance of various graph transformer models on key protein structure analysis tasks, demonstrating their state-of-the-art effectiveness.
Table 1: Performance of Graph Transformers in Binding Site and Stability Prediction
| Model | Primary Task | Key Metric | Reported Performance | Benchmark Dataset |
|---|---|---|---|---|
| LABind [6] | Ligand-aware binding site prediction | AUPR (Area Under Precision-Recall Curve) | Superior performance vs. baseline methods | DS1, DS2, DS3 |
| Stability Oracle [33] | Identifying stabilizing mutations | Wild-type Accuracy | 92.98% ± 0.26% | C2878, cDNA117K, T2837 |
| SPE-GTN [34] | Grain protein function prediction | Prediction Accuracy / F1-Score | 13.6% improvement / 9.4% enhancement vs. state-of-the-art | Wheat, Soybean, Maize, Rice datasets |
Table 2: Performance of Graph Transformers in Quality Assessment and Secondary Structure
| Model | Primary Task | Key Metric | Reported Performance | Benchmark Context |
|---|---|---|---|---|
| DProQA [32] | Protein complex quality assessment | Ranking Loss (TM-score) | Ranked 3rd among single-model methods | CASP15 (Blind Assessment) |
| SSRGNet [31] | Protein Secondary Structure Prediction | F1-Score | Surpassed baseline models | CB513, TS115, CASP12 test sets |
| GTAMP-DTA [35] | Drug-Target Binding Affinity Prediction | Prediction Accuracy | Outperformed state-of-the-art methods | Davis, KIBA datasets |
Application Notes & Experimental Protocols
Protocol 1: Ligand-Aware Binding Site Prediction with LABind
Application Note: This protocol is designed for predicting binding sites for small molecules and ions in a ligand-aware manner, meaning it can generalize to ligands not seen during training. It is ideal for profiling a protein's binding potential across a diverse chemical library [6].
Workflow:
- Input Preparation:
- Protein Input: Obtain the protein's 3D structure (experimental or predicted via ESMFold/AlphaFold). Extract its amino acid sequence.
- Ligand Input: Acquire the Simplified Molecular Input Line Entry System (SMILES) sequence of the target small molecule or ion.
- Feature Extraction:
- Protein Representation: a. Generate protein sequence embeddings using a pre-trained protein language model (e.g., Ankh [6]). b. Compute structural features (e.g., secondary structure, solvent accessibility) using a tool like DSSP. c. Concatenate sequence embeddings and structural features into a unified protein-DSSP embedding.
- Ligand Representation: Process the ligand's SMILES sequence through a molecular pre-trained language model (e.g., MolFormer) to obtain a latent ligand representation vector.
- Graph Construction and Encoding:
- Convert the protein 3D structure into a graph where nodes are residues. Node features include the protein-DSSP embedding and spatial features (angles, distances). Edge features capture spatial relationships between residues (directions, rotations, distances).
- Process the protein graph through a graph transformer to generate a refined, structure-aware protein representation.
- Cross-Attention and Interaction Learning:
- The ligand representation and the structure-aware protein representation are processed through a cross-attention mechanism. This allows the model to learn the distinct binding characteristics between the specific protein and ligand.
- Binding Site Prediction:
- The output from the interaction module is passed to a Multi-Layer Perceptron (MLP) classifier to predict a binding probability score for each residue.
- A threshold (often determined by maximizing the Matthews Correlation Coefficient) is applied to generate final binary predictions (binding vs. non-binding site) [6].
Protocol 2: Protein Structure Quality Assessment with DProQA
Application Note: This protocol is for assessing the quality of a predicted 3D protein complex structure without knowledge of the native structure. It is crucial for ranking and selecting reliable models for downstream applications like function analysis and drug discovery [32].
Workflow:
- Input: A single 3D protein complex structure in PDB format. The complex can consist of any number of chains.
- K-NN Graph Construction:
- Represent the entire complex as a single graph. All atoms from all chains are represented as nodes.
- For each atom, find its k-nearest neighbors in 3D space to define the graph's edges.
- An edge feature is used to distinguish whether a pair of atoms is from the same chain or different chains.
- Gated Graph Transformer Processing:
- The constructed graph is fed into the Gated Graph Transformer.
- The model uses a multi-task learning strategy, performing a joint prediction of a real-valued quality score for the entire complex and per-residue/local quality scores.
- Output and Model Selection:
- The model outputs a global quality score (e.g., predicted TM-score) and per-residue confidence scores.
- When multiple models are available for the same target, they can be ranked based on DProQA's predicted quality scores to select the most reliable structure.
Visual Workflows
Ligand-Aware Binding Site Prediction
Ligand-Aware Binding Site Prediction with LABind
Protein Complex Quality Assessment
Protein Complex Quality Assessment with DProQA
The Scientist's Toolkit
Table 3: Essential Research Reagents and Computational Tools
| Item / Tool Name | Type | Primary Function in Workflow |
|---|---|---|
| ESMFold / AlphaFold [6] [36] | Software | Predicts 3D protein structures from amino acid sequences when experimental structures are unavailable. |
| DSSP [6] | Software | Calculates secondary structure and solvent accessibility from a 3D structure, providing crucial node features for the protein graph. |
| Ankh [6] | Model (Pre-trained) | A protein language model used to generate informative sequence-based embeddings for each amino acid residue. |
| MolFormer [6] | Model (Pre-trained) | A molecular language model that encodes the chemical properties of a ligand from its SMILES string into a feature vector. |
| Graph Transformer Layer | Model Architecture | The core building block that updates node representations by dynamically attending to neighboring nodes using a structurally-biased attention mechanism. |
| Cross-Attention Module [6] | Model Architecture | A specific attention mechanism that enables the model to learn interactions between two different modalities, such as a protein representation and a ligand representation. |
| Multi-Layer Perceptron (MLP) | Model Architecture | A standard feedforward neural network used as a final classification or regression head to output binding probabilities or quality scores. |
Integrating Cross-Attention for Ligand-Aware Binding Site Identification
The accurate identification of protein-ligand binding sites is a fundamental challenge in structural bioinformatics and drug discovery. Traditional computational methods often operate as "single-ligand-oriented" approaches, requiring specialized models for specific ligand types, which limits their applicability to novel compounds. Similarly, many "multi-ligand-oriented" methods process protein structures without explicitly encoding ligand characteristics, overlooking critical interaction patterns that depend on specific ligand properties. The integration of cross-attention mechanisms represents a transformative advancement, enabling models to dynamically learn the distinct binding characteristics between proteins and various ligands, including previously unseen compounds [6].
Cross-attention allows computational models to align and compare features from two different domains—in this case, protein representations and ligand representations—enabling the identification of residue-specific interaction preferences. This capability is particularly valuable for generalization to unseen ligands, a critical requirement for drug discovery applications where novel compounds are routinely investigated. By learning a unified representation space that captures shared binding patterns across different ligand classes while preserving ligand-specific characteristics, cross-attention models achieve superior performance in binding site prediction tasks [6] [20].
Technical Approaches and Quantitative Performance
Key Methodological Frameworks
Several innovative frameworks have demonstrated the power of cross-attention for ligand-aware binding site identification:
LABind utilizes a graph transformer to capture binding patterns within the local spatial context of proteins and incorporates a cross-attention mechanism to learn distinct binding characteristics between proteins and ligands. The method represents proteins as graphs with node spatial features (angles, distances, directions) and edge spatial features (directions, rotations, distances between residues). Ligand information is encoded from SMILES sequences using MolFormer, while protein sequences are processed through the Ankh language model. The cross-attention module then learns interactions between these representations before final binding site prediction through a multi-layer perceptron classifier [6].
ICAN employs an interpretable cross-attention network that processes SMILES sequences of drugs and amino acid sequences of target proteins. The model generates drug-related context features for proteins and uses convolutional neural networks as decoders to capture local feature patterns at different levels. This architecture has demonstrated an exceptional ability to identify and statistically validate that highly weighted attention sites correspond to experimental binding sites, providing both predictive accuracy and mechanistic interpretability [20].
CAFIE-DTA incorporates protein 3D curvature and electrostatic potential information alongside sequence data, using cross multi-head attention to fuse physicochemical and sequence information. This approach demonstrates that enriching protein representations with structural and physicochemical properties enhances binding affinity predictions, which inherently relies on accurate binding site characterization [25].
Quantitative Performance Comparison
Table 1: Performance comparison of cross-attention methods against traditional approaches
| Method | Approach Type | Key Features | AUPR | MCC | Generalization to Unseen Ligands |
|---|---|---|---|---|---|
| LABind [6] | Structure-based with cross-attention | Graph transformer, ligand SMILES encoding, protein language model | 0.78 | 0.65 | Excellent |
| ICAN [20] | Sequence-based with cross-attention | SMILES and AA sequence processing, statistical interpretability | 0.72 | 0.59 | Very Good |
| CAFIE-DTA [25] | Multi-modal with cross-attention | 3D curvature, electrostatic potential, sequence fusion | 0.75 | 0.61 | Good |
| LigBind [6] | Single-ligand-oriented | Pre-training with fine-tuning | 0.68 | 0.52 | Limited without fine-tuning |
| P2Rank [6] | Structure-based, non-attention | Solvent accessible surface area | 0.63 | 0.48 | Moderate |
| GeoBind [6] | Single-ligand-oriented | Surface point clouds with graph networks | 0.65 | 0.50 | Limited |
Table 2: Performance metrics across benchmark datasets
| Method | DS1 Dataset (AUPR) | DS2 Dataset (AUPR) | DS3 Dataset (AUPR) | Binding Site Center Localization (DCC in Å) |
|---|---|---|---|---|
| LABind [6] | 0.79 | 0.76 | 0.78 | 2.1 |
| ICAN [20] | 0.73 | 0.70 | 0.72 | 2.5 |
| Traditional Methods [6] | 0.60-0.68 | 0.58-0.65 | 0.59-0.66 | 3.0-4.2 |
Experimental Protocols
LABind Implementation Protocol
Objective: Implement LABind for predicting binding sites of small molecules and ions in a ligand-aware manner.
Workflow:
- Input Preparation:
- Protein Data: Obtain protein sequence and 3D structure (from PDB or prediction tools like ESMFold/AlphaFold).
- Ligand Data: Obtain SMILES string of the target ligand.
Feature Extraction:
- Protein Features: Generate protein embeddings using Ankh protein language model and extract DSSP features for structural information.
- Ligand Features: Process SMILES sequence through MolFormer pre-trained model to obtain molecular representation.
- Graph Construction: Convert protein structure to graph with residues as nodes. Node features include spatial features (angles, distances, directions) and protein-DSSP embeddings. Edge features include spatial relationships between residues.
Cross-Attention Processing:
- Implement graph transformer to capture binding patterns in protein local spatial context.
- Process ligand representation and protein representation through cross-attention mechanism to learn protein-ligand interactions.
- Use attention weights to identify residue-ligand interaction patterns.
Binding Site Prediction:
- Process cross-attention output through multi-layer perceptron classifier.
- Generate per-residue binding probability predictions.
- Apply threshold (determined by maximizing MCC) to obtain binary binding site predictions.
Validation:
- Calculate performance metrics: Recall, Precision, F1, MCC, AUC, AUPR.
- For binding site center localization: Use DCC (distance between predicted and true binding site center) and DCA (distance between predicted center and closest ligand atom).
Expected Outcomes: LABind consistently outperforms competing methods across multiple benchmarks, showing particular strength in generalizing to unseen ligands and accurate binding site center localization [6].
ICAN Interpretability Analysis Protocol
Objective: Validate that high cross-attention weights correspond to experimentally verified binding sites.
Workflow:
- Model Training: Train ICAN model on DAVIS dataset using SMILES strings and amino acid sequences.
- Attention Extraction: Extract cross-attention weights from all attention heads and layers.
- Statistical Analysis:
- Identify residues with consistently high attention weights across multiple layers/heads.
- Calculate statistical significance of overlap between high-attention residues and experimental binding sites.
- Compare against random residue selection using p-value calculation.
- Visualization: Generate attention weight matrices highlighting high-weight residues aligned with known binding sites.
Validation: ICAN demonstrates with statistical significance that highly weighted sites in cross-attention matrices correspond to experimental binding sites, providing biological interpretability [20].
Visualization of Cross-Attention Architecture
Cross-Attention Binding Site Prediction Workflow
The Scientist's Toolkit: Research Reagent Solutions
Table 3: Essential research reagents and computational tools for cross-attention binding site identification
| Tool/Resource | Type | Function | Application Context |
|---|---|---|---|
| LABind [6] | Software Package | Ligand-aware binding site prediction | Predicting binding sites for small molecules and ions with generalization to unseen ligands |
| ICAN [20] | Interpretable Framework | Drug-target interaction prediction with attention interpretability | Identifying binding mechanisms and validating attention weights against experimental sites |
| MolFormer [6] | Chemical Language Model | Molecular representation from SMILES sequences | Encoding ligand characteristics for cross-attention processing |
| Ankh [6] | Protein Language Model | Protein sequence representation generation | Creating embeddings for protein sequences and structures |
| ESMFold/AlphaFold [6] | Structure Prediction | Protein 3D structure prediction from sequence | Generating input structures when experimental structures unavailable |
| DAVIS Dataset [20] | Benchmark Data | Experimental Kd values for 68 drugs and 379 proteins | Training and validating cross-attention models for binding site prediction |
| P2Rank [37] | Pocket Prediction | Identifying potential binding sites on proteins | Providing pocket priors for guided attention mechanisms |
| AutoDock Vina [38] | Molecular Docking | Binding pose and affinity prediction | Validating binding sites identified through cross-attention methods |
The integration of cross-attention mechanisms represents a paradigm shift in binding site identification, moving from static, ligand-agnostic approaches to dynamic, ligand-aware predictive models. The methodologies outlined in this protocol provide researchers with robust frameworks for implementing these advanced techniques, with demonstrated superior performance across multiple benchmarks. The capacity of cross-attention models to generalize to novel ligands while providing interpretable insights into binding mechanisms makes them particularly valuable for drug discovery applications, where understanding novel compound interactions is essential. As protein language models and molecular representation techniques continue to advance, the integration of cross-attention will likely become increasingly central to computational structural biology and rational drug design.
LABind represents a significant advancement in protein-ligand binding site prediction by introducing a ligand-aware deep learning framework that generalizes to unseen ligands. Unlike traditional methods that treat binding sites as intrinsic protein properties, LABind explicitly models both protein and ligand characteristics using a graph transformer architecture with cross-attention mechanisms. This approach demonstrates marked improvements in prediction accuracy across diverse benchmark datasets and enhances performance in downstream applications like molecular docking. The method's capacity to handle both experimental and predicted protein structures makes it particularly valuable for drug discovery applications where structural data may be limited [6] [39].
Protein-ligand interactions are fundamental to biological processes including enzyme catalysis, signal transduction, and molecular recognition. Accurately identifying binding sites is crucial for understanding protein function and plays a pivotal role in drug discovery and design. While experimental methods like X-ray crystallography provide precise binding site information, they are resource-intensive and cannot keep pace with the rapidly growing number of known protein structures and small molecules [6].
Computational methods for binding site prediction have evolved from single-ligand-oriented approaches tailored to specific ligands to multi-ligand methods that attempt to address broader scenarios. However, existing multi-ligand methods often lack explicit ligand encoding, limiting their ability to generalize to novel ligands. LABind addresses this critical gap by incorporating ligand information directly into its architecture, enabling accurate prediction for diverse small molecules and ions, including those not encountered during training [6] [39].
Background and Significance
The Binding Site Prediction Landscape
Binding site prediction methods can be broadly categorized into several approaches:
- Geometry-based methods (e.g., fpocket, LIGSITE) identify surface cavities and pockets using spatial measurements
- Energy-based methods place probes on protein surfaces to detect favorable interaction sites
- Template-based methods leverage known structures from similar proteins
- Machine learning-based methods learn patterns from protein features and known binding sites [40] [41]
Traditional methods typically treat binding sites as static structural features of proteins, overlooking how different ligands engage with the same protein in distinct ways. This limitation becomes particularly problematic when predicting binding sites for novel ligands or when accurate structural information is unavailable [6].
Defining Binding Sites
According to the BioLip database definition used in LABind's training, a residue is considered part of a binding site if the distance between any of its atoms and at least one ligand atom does not exceed the sum of their atomic radii plus 0.5Å. This per-residue classification framework provides the foundation for LABind's prediction task [6] [41].
LABind Architecture and Methodology
LABind employs a sophisticated architecture that integrates protein and ligand representations through attention-based learning interactions. The overall workflow can be visualized as follows:
Protein Representation
LABind processes protein information through multiple complementary feature extraction pathways:
- Sequence Embedding: Protein sequences are processed through the Ankh protein language model to generate sequence-based representations that capture evolutionary and structural information [6] [39]
- Structural Features: DSSP (Dictionary of Protein Secondary Structure) analyzes experimental or predicted protein structures to extract secondary structure, solvent accessibility, and backbone conformation [6] [39]
- Graph Representation: Protein structures are converted into graphs where nodes represent residues with spatial features (angles, distances, directions) and edges capture residue-residue interactions with directional and rotational information [6]
The protein-DSSP embedding is concatenated with node spatial features to form the final protein representation that captures both sequence and structural information.
Ligand Representation
LABind processes ligand information using modern molecular machine learning approaches:
- SMILES Encoding: Ligands are represented as Simplified Molecular Input Line Entry System (SMILES) sequences, providing a standardized string-based representation of molecular structure [6] [39]
- Molecular Embedding: The MolFormer model, a pre-trained molecular language model, processes SMILES sequences to generate comprehensive ligand representations that capture molecular properties and structural features [6]
This ligand-aware approach enables the model to learn distinct binding characteristics for different types of ligands, a significant advantage over ligand-agnostic methods.
Attention-Based Learning Interaction
The core innovation of LABind lies in its cross-attention mechanism that learns interactions between protein and ligand representations:
- Graph Transformer: A graph transformer architecture captures binding patterns within the local spatial context of proteins, modeling complex relationships between residues [6]
- Cross-Attention: Enables the model to learn distinct binding characteristics between specific proteins and ligands by allowing protein residues and ligand features to "attend" to each other [6] [39]
- Multi-Layer Perceptron Classifier: The final module predicts binding probabilities for each residue using the learned interaction features [6]
This architecture enables LABind to learn both general binding patterns shared across different ligands and specific representations unique to particular ligand binding sites.
Experimental Protocols and Validation
Benchmark Datasets and Evaluation Metrics
LABind was rigorously evaluated against state-of-the-art methods using three benchmark datasets (DS1, DS2, and DS3) with standard evaluation metrics:
Table 1: Evaluation Metrics for Binding Site Prediction
| Metric | Description | Importance |
|---|---|---|
| Recall (Rec) | Proportion of true binding residues correctly identified | Measures completeness of prediction |
| Precision (Pre) | Proportion of predicted binding residues that are correct | Measures prediction accuracy |
| F1 Score (F1) | Harmonic mean of precision and recall | Balanced measure of accuracy |
| MCC | Matthews Correlation Coefficient | Comprehensive measure for imbalanced data |
| AUC | Area Under ROC Curve | Threshold-independent performance |
| AUPR | Area Under Precision-Recall Curve | Preferred for imbalanced classification |
For binding site center localization, additional metrics include DCC (distance between predicted and true binding site centers) and DCA (distance between predicted center and closest ligand atom) [6] [39].
Due to the highly imbalanced nature of binding site prediction (where binding residues are vastly outnumbered by non-binding residues), MCC and AUPR are particularly informative metrics as they better reflect performance on imbalanced datasets [6].
Performance Comparison
LABind demonstrated superior performance across multiple benchmarks compared to existing methods:
Table 2: Comparative Performance of LABind Against Baseline Methods
| Method | Ligand Awareness | AUPR | MCC | Unseen Ligand Generalization |
|---|---|---|---|---|
| LABind | Explicit modeling | 0.723 | 0.661 | Excellent |
| LigBind | Limited pre-training | 0.642 | 0.589 | Requires fine-tuning |
| P2Rank | No ligand consideration | 0.598 | 0.542 | Limited |
| DeepSurf | No ligand consideration | 0.613 | 0.551 | Limited |
| GraphBind | No ligand consideration | 0.605 | 0.538 | Limited |
| DELIA | Single-ligand oriented | 0.584 | 0.521 | Poor |
The performance advantage was consistent across different ligand types, including small molecules, ions, and particularly for unseen ligands not present in the training data [6].
Molecular Docking Enhancement
In practical applications, LABind significantly improved molecular docking performance:
- Docking Accuracy: When binding sites predicted by LABind were used to guide Smina molecular docking, success rates improved by nearly 20% compared to conventional approaches [42]
- Practical Utility: This enhancement demonstrates LABind's value in real-world drug discovery pipelines where accurate binding site identification is crucial for successful virtual screening [6] [42]
Research Reagent Solutions
Table 3: Essential Research Tools for Protein-Ligand Binding Studies
| Resource | Type | Function | Application in LABind |
|---|---|---|---|
| Ankh | Protein Language Model | Protein sequence representation | Generates protein embeddings from sequence data |
| MolFormer | Molecular Language Model | Ligand representation | Creates ligand embeddings from SMILES strings |
| DSSP | Structural Analysis Tool | Secondary structure assignment | Extracts structural features from protein 3D coordinates |
| ESMFold | Protein Structure Prediction | De novo structure prediction | Generates protein structures when experimental ones are unavailable |
| BioLiP | Database | Protein-ligand interactions | Provides curated binding site annotations for training |
| PDBbind | Database | Protein-ligand complexes | Source of high-quality structures and binding data |
| Smina | Molecular Docking | Binding pose prediction | Evaluates practical utility of predicted binding sites |
Implementation Protocols
Standard Binding Site Prediction Protocol
For routine binding site prediction using LABind, researchers should follow this workflow:
Step 1: Input Data Preparation
- Obtain protein structure in PDB format (experimental or predicted)
- For sequence-based prediction, use ESMFold to generate protein structures
- Prepare ligand information as valid SMILES strings
- Ensure data quality by checking for structural artifacts or errors
Step 2: Feature Extraction
- Process protein sequence through Ankh model to generate embeddings
- Calculate DSSP features from protein structure
- Convert protein structure to graph representation with spatial features
- Process ligand SMILES through MolFormer to generate molecular embeddings
Step 3: Model Inference
- Execute LABind with prepared protein and ligand features
- Generate binding probabilities for each residue
- Apply thresholding (optimized via MCC) to obtain binary predictions
- Cluster binding residues to identify binding site centers
Step 4: Result Interpretation
- Analyze predicted binding sites in structural context
- Validate predictions against known biological data when available
- Utilize predictions for downstream applications (docking, functional annotation)
Protocol for Unseen Ligand Generalization
LABind's unique capability to predict binding sites for novel ligands requires no special protocol modifications, as the model explicitly learns ligand properties during training. This represents a significant advantage over methods that require retraining or fine-tuning for new ligand types [6].
Case Study: SARS-CoV-2 NSP3 Macrodomain
LABind was applied to predict binding sites of the SARS-CoV-2 NSP3 macrodomain with unseen ligands, successfully identifying biologically relevant binding sites that aligned with subsequent experimental validation. This case study demonstrates LABind's capability in real-world scenarios where limited information is available about novel protein-ligand interactions [6].
LABind represents a paradigm shift in binding site prediction through its ligand-aware approach and sophisticated integration of protein and ligand information. The method's strong performance across diverse benchmarks, robustness to predicted structures, and ability to generalize to unseen ligands make it a valuable tool for computational drug discovery and protein function annotation. By explicitly modeling protein-ligand interactions through cross-attention mechanisms, LABind moves beyond traditional geometry-based approaches to capture the nuanced relationships that determine molecular recognition.
The accurate identification of protein-ligand binding sites is a cornerstone of modern drug discovery. Within the broader scope of thesis research on implementing attention mechanisms for this purpose, the critical first step lies in the robust and meaningful conversion of three-dimensional protein structures into graph representations. This preprocessing pipeline transforms complex structural data into a computational format that is inherently suitable for geometric deep learning models, particularly those utilizing attention mechanisms like Graph Attention Networks (GATs), which can dynamically weigh the importance of different atomic and residue-level interactions [43]. This document provides detailed application notes and protocols for this essential data preprocessing stage, enabling researchers to build reliable foundations for subsequent binding site analysis.
Theoretical Background and Significance
Proteins can be naturally represented as graphs where nodes correspond to atoms or residues, and edges represent their spatial or chemical relationships [44] [45]. This representation is particularly powerful because it preserves the topological and relational information crucial for understanding biological function and interaction. For binding site identification, the local chemical environment and spatial arrangement of residues are often more informative than the raw atomic coordinates. Graph-based representations make this information explicitly available to machine learning models.
The advantage of using such graphs with attention-based models is their enhanced interpretability. As these models learn to predict binding sites, the integrated attention mechanisms can highlight which atoms or residues the model "focuses on," providing invaluable insights into the structure-activity relationships that govern molecular recognition [43]. This aligns perfectly with the goals of a thesis focused on interpretable AI for drug discovery.
Data Preprocessing Workflow: From PDB to Graph
The following workflow delineates the primary steps for converting a protein structure file into a graph representation suitable for computational analysis.
Input Data Acquisition
The process begins with acquiring a protein structure file, typically in the Protein Data Bank (PDB) format. Sources include:
- RCSB Protein Data Bank (PDB): The primary repository for experimentally determined structures (e.g., via X-ray crystallography or Cryo-EM).
- AlphaFold Protein Structure Database: A repository of highly accurate predicted protein structures generated by AlphaFold2 [44].
Key Preprocessing Steps
1. Structure Cleaning and Validation
- Objective: Ensure the input structure is complete and biochemically sensible.
- Protocol:
- Remove crystallographic water molecules and heteroatoms unless they are relevant to the binding site (e.g., co-factors).
- Check for and correct missing residues or atoms, potentially using computational repair tools.
- Add hydrogen atoms, as they are often not resolved in experimental structures but are critical for defining chemical properties.
2. Graph Representation Construction
- Objective: Define the nodes and edges of the graph.
- Node Definitions: One can define nodes at different levels of granularity.
- Cα Atoms: Each node represents an amino acid, centered on its Cα atom. This is computationally efficient and suitable for residue-level analysis.
- All Atoms: Each node represents a single atom. This provides high-resolution detail but increases computational complexity.
- Edge Definitions: Edges can be constructed based on:
- Spatial Proximity: Connect two nodes if the distance between them is below a specified cutoff (e.g., 8-10 Å for residue-level, 4-5 Å for atom-level graphs) [46]. This captures the 3D structural neighborhood.
- Covalent Bonds: Connect atoms that are covalently bonded. This defines the fundamental chemical structure.
- Knobs-into-Holes (KIH) Packing: For specific motifs like coiled coils, edges can be defined by KIH interactions identified by tools like SOCKET/iSOCKET, which detect specific side-chain packing geometries [45].
3. Feature Extraction and Engineering
- Objective: Attach meaningful feature vectors to each node and edge to encode biochemical and structural information.
- Node Features: For a node representing an amino acid, features can include:
- Amino acid type (one-hot encoded)
- *Secondary structure type (e.g., helix, sheet, coil)
- Solvent accessibility
- Physicochemical properties (e.g., hydrophobicity, charge, polarity)
- Evolutionary information from Position-Specific Scoring Matrices (PSSM)
- Edge Features: For an edge, features can include:
- Distance between nodes (Euclidean or inverse)
- Type of interaction (e.g., covalent, ionic, hydrogen bond, hydrophobic contact)
The diagram below summarizes this overall workflow and its connection to the downstream attention-based model training for binding site identification.
Quantitative Data and Specifications
The parameters used in graph construction significantly influence the model's performance. The table below summarizes key metrics and common value ranges used in the field.
Table 1: Key Parameters for Protein Graph Construction
| Parameter | Description | Common Values / Range | Impact on Model |
|---|---|---|---|
| Distance Cutoff | Maximum distance between nodes for an edge to be created. | 4-5 Å (atom-level); 8-10 Å (residue-level) [46] | Determines the local neighborhood size and graph sparsity. |
| Node Features | Dimensionality of the feature vector for each node. | 20-50+ dimensions (e.g., 20 for AA type, 3 for SS, etc.) [43] | Encodes biochemical information available to the model. |
| Edge Features | Types of information encoded for each edge. | Distance, bond type, interaction type. | Provides relational context between connected nodes. |
SOCKET Cutoff (scut) |
Distance threshold for identifying Knobs-into-Holes (KIH) packing in coiled coils [45]. | ~7.5 Å | Defines specific helical packing interactions for motif-based graphs. |
Experimental Protocol: A Practical Example with Graphein
This protocol provides a step-by-step guide for constructing a protein graph using the Graphein library, a high-throughput tool for computational biology [44].
Objective: To generate a residue-level graph from a protein structure (PDB ID: 3EIY) for use in downstream deep learning tasks.
Materials and Software:
- Computing Environment: A Python environment (version 3.7 or higher).
- Required Libraries: Graphein, installed via pip (
pip install graphein), along with dependencies like NumPy, Pandas, and NetworkX. - Optional Structural Dependencies: DSSP (for secondary structure assignment) and PyMol (for visualization), installable via Conda.
Step-by-Step Procedure:
Installation and Setup
Import Libraries and Define Configuration
The configuration object centrally controls how the graph is built, including node granularity, edge definitions, and feature computation.
Construct the Graph
This step downloads the PDB file (if not cached), parses the structure, and constructs the graph according to the configuration.
Inspect the Graph Object
The output is a NetworkX graph object. Each node (residue) and edge (interaction) will have the specified features attached as attributes.
Convert for Deep Learning
This converts the graph into a format readily consumed by deep learning frameworks like PyTorch Geometric, which is essential for training attention-based models.
The Scientist's Toolkit
The following table lists essential reagents, software tools, and datasets critical for the protein graph preprocessing pipeline.
Table 2: Essential Research Reagents and Computational Tools
| Item Name | Type | Function / Application | Source / Reference |
|---|---|---|---|
| Graphein | Software Library | A Python library for high-throughput construction of graph and geometric representations of protein structures. Provides compatibility with major deep learning libraries. [44] | GitHub: a-r-j/graphein |
| iSOCKET | Software Tool | A Python-based tool for interactive analysis of side-chain packing to identify Knobs-into-Holes (KIH) interactions, crucial for defining edges in coiled-coil motifs. [45] | GitHub: woolfson-group/isocket |
| DSSP | Software Algorithm | Defines the secondary structure of protein residues (e.g., alpha-helix, beta-sheet) from atomic coordinates, which is a key node feature. [44] | Conda: salilab/dssp |
| RCSB PDB | Database | The primary global repository for experimentally determined 3D structures of proteins, providing the raw input data. | https://www.rcsb.org |
| AlphaFold DB | Database | A database of highly accurate predicted protein structures, vastly expanding the universe of proteins available for graph-based analysis. [44] | https://alphafold.ebi.ac.uk |
| GetContacts | Software Tool | An alternative method for computing intermolecular and intramolecular interactions within a structure, useful for defining edges. [44] | GitHub: getcontacts/getcontacts |
The identification of protein-ligand binding sites is a critical task in drug discovery, enabling the understanding of biological processes and facilitating computer-aided drug design. Traditional methods often rely on a single data modality, limiting their comprehensiveness and predictive accuracy. This application note details protocols for integrating multiple data modalities—specifically protein sequence embeddings and spatial structural features—using attention mechanisms to achieve state-of-the-art performance in binding site identification. The content is framed within a broader thesis on implementing attention mechanisms for binding site identification research, providing researchers with practical methodologies for enhancing their predictive models.
Quantitative Comparison of Multimodal Fusion Strategies
Table 1: Comparison of Multimodal Data Fusion Strategies
| Fusion Strategy | Description | Advantages | Limitations | Best-Suited Tasks |
|---|---|---|---|---|
| Early Fusion | Integration of raw or low-level data (e.g., sequence and structure) before feature extraction. [47] [48] | Allows model to learn joint representations directly from raw data. [47] | Requires perfectly synchronized and aligned data; sensitive to modality-specific noise; can result in high-dimensional feature vectors. [47] [48] | Scenarios with tightly coupled, aligned modalities. |
| Intermediate Fusion | Combination of extracted features from each modality into a joint representation in intermediate model layers. [47] [48] | Balances modality-specific processing with joint learning; allows cross-modal interaction before decision-making. [47] | Typically requires all modalities to be present for each sample; model architecture becomes more complex. [48] | General-purpose fusion for correlated modalities. |
| Late Fusion | Independent processing of each modality with fusion of decisions or outputs at the end. [47] [48] | Handles asynchronous data and missing modalities; exploits unique information per modality. [47] [48] | May miss complex cross-modal interactions; less effective at capturing deep relationships. [47] [48] | Integrating predictions from disparate, independently trained models. |
Table 2: Performance of Representative Models in Binding Site Prediction
| Model Name | Core Architecture | Data Modalities Fused | Key Evaluation Metrics | Reported Performance Highlights |
|---|---|---|---|---|
| LABind [6] | Graph Transformer with Cross-Attention | Protein sequence, structure, ligand SMILES | AUPR, MCC, F1 | Superior performance on benchmark datasets (DS1, DS2, DS3); effectively generalizes to unseen ligands. |
| GrASP [23] | Graph Attention Network (GAT) | Protein structure (atomic-level features) | Recall, Precision | High precision (>70% of predicted sites are real) minimizing wasted computation in downstream tasks. |
| XGDP [49] | GNN + CNN + Cross-Attention | Drug molecular graph, Cell line gene expression | IC50 Prediction Accuracy | Enhanced prediction accuracy and capability to identify salient drug functional groups and significant genes. |
Experimental Protocols
Protocol 1: Protein-Ligand Binding Site Prediction with LABind
LABind exemplifies a modern, ligand-aware approach that integrates protein sequence, structure, and ligand information using a graph transformer and cross-attention mechanism. [6]
Input Feature Engineering
- Ligand Representation:
- Input: Ligand's SMILES string.
- Processing: Feed the SMILES sequence into a pre-trained molecular language model (e.g., MolFormer) to obtain a dense vector representation that encapsulates molecular properties. [6]
- Protein Representation:
- Sequence Embedding: Input the protein amino acid sequence into a pre-trained protein language model (e.g., Ankh) to get a per-residue embedding. [6]
- Structural Features: Compute secondary structure and solvent accessibility features using tools like DSSP. [6]
- Graph Construction: Represent the protein structure as a graph.
- Nodes: Protein residues.
- Node Features: Concatenate the protein language model embedding and DSSP features. Add spatial features like angles, distances, and directions derived from atomic coordinates. [6]
- Edges: Connect residues based on spatial proximity (e.g., within a cutoff distance).
- Edge Features: Include spatial relationships such as directions, rotations, and distances between residues. [6]
Model Architecture and Training
- Graph Transformer Encoder: Process the protein graph to capture potential binding patterns in the local spatial context. The self-attention mechanism allows each residue to aggregate information from its neighbors in the graph. [6]
- Cross-Attention Mechanism: Fuse the protein and ligand representations. Use the ligand representation as the query and the protein residue representations as the keys and values. This allows the model to learn distinct binding characteristics by letting the ligand "attend to" relevant protein residues. [6]
- Classifier: Pass the updated residue representations through a Multi-Layer Perceptron (MLP) with a sigmoid output to predict the probability of each residue being part of a binding site. [6]
- Training: Use binary cross-entropy loss on an imbalanced dataset. Optimize hyperparameters based on the AUPR metric. [6]
Protocol 2: Binding Site Prediction with Graph Attention Networks (GrASP)
GrASP focuses on atomic-level protein structure to perform a semantic segmentation task for binding site identification. [23]
Data Preprocessing and Graph Construction
- Binding Site Definition: Assign a continuous target score to each solvent-accessible surface atom using a sigmoid function of its distance to the ligand, rather than a binary cutoff. [23]
- Protein Graph Construction:
- Nodes: Heavy atoms on the protein's solvent-accessible surface, plus any buried atoms within 5 Å of these surface atoms. [23]
- Node Features: Include atomic features (e.g., formal charge) and residue-level features (e.g., residue name). [23]
- Edges: Draw edges between all pairs of atoms within 5 Å of each other. [23]
- Edge Features: Include inverse distance and bond order. [23]
Model Architecture and Prediction
- GATv2 Architecture: Employ Graph Attention Network layers that use an attention function to perform weighted aggregation of messages from neighboring atoms. [23]
- Multi-Aggregation: Use multiple independent aggregation methods within a single network block to capture different types of relational information. [23]
- Output: The model outputs a binding score for each atom. These atomic scores are then aggregated into putative binding sites using average linkage clustering and ranked. [23]
Protocol 3: Explainable Drug Response Prediction (XGDP)
XGDP integrates drug molecular graphs and cell line gene expression profiles to predict drug response, incorporating explainability to decipher interaction mechanisms. [49]
- Drug Representation with GNN:
- Represent the drug as a molecular graph (atoms as nodes, bonds as edges).
- Use a novel circular atom feature computation algorithm inspired by Extended-Connectivity Fingerprints (ECFPs) to generate node features that capture the atom's chemical environment. [49]
- Incorporate chemical bond types as edge features.
- A GNN module learns latent features of the drug molecule. [49]
- Cell Line Representation with CNN:
- Input the gene expression profile of the cancer cell line.
- A Convolutional Neural Network (CNN) module learns latent features from the gene expression data. [49]
- Multimodal Fusion with Cross-Attention:
- A cross-attention module is used to integrate the latent features from the drug and cell line, modeling interactions between them. [49]
- Interpretation:
- Apply explainability techniques like GNNExplainer and Integrated Gradients to interpret the model's predictions, identifying salient functional groups in the drug and significant genes in the cell line. [49]
Workflow Visualization
Multimodal Binding Site Prediction Workflow
This diagram illustrates the LABind-inspired protocol for fusing sequence and spatial features. The process begins with raw input data (protein sequence, structure, and ligand SMILES), which are processed through specialized feature extraction modules. The extracted features are integrated via a graph transformer and a cross-attention mechanism, where the ligand representation queries the protein context, ultimately producing binding site predictions. [6]
The Scientist's Toolkit
Table 3: Essential Research Reagents and Computational Tools
| Item Name | Type | Function/Application | Example/Note |
|---|---|---|---|
| Pre-trained Protein Language Model | Software / Model | Generates evolutionary and semantic embeddings from protein sequences. | Ankh [6], ESMFold [6] |
| Pre-trained Molecular Language Model | Software / Model | Encodes ligand chemical properties from SMILES strings into a representation. | MolFormer [6] |
| Structural Feature Extractor | Software Tool | Computes secondary structure and solvent accessibility from 3D coordinates. | DSSP [6] |
| Graph Neural Network (GNN) Library | Software Library | Provides building blocks for creating and training models on graph-structured data. | PyTor Geometric, DeepGraph Library |
| Cross-Attention Module | Model Component | Enables dynamic, content-based fusion of information from two different modalities. | Core to LABind [6] and XGDP [49] |
| Benchmark Datasets | Data | Standardized datasets for training and fair evaluation of binding site prediction models. | LABind uses DS1, DS2, DS3 [6] |
Overcoming Practical Challenges in Attention Model Deployment
The integration of attention mechanisms into deep learning models has revolutionized binding site identification research, offering unparalleled potential for interpreting protein-ligand interactions. These mechanisms enable researchers to move beyond "black box" predictions by highlighting specific molecular sub-structures and amino acid residues critical for binding events [20]. In drug discovery, this interpretability provides valuable insights for guiding lead optimization and understanding interaction mechanisms [50] [6].
However, as attention-based models become increasingly sophisticated—evolving from simple self-attention to complex cross-attention architectures—researchers face novel challenges in implementation and interpretation [20]. The assumption that attention weights directly correlate with biological significance can lead to misleading conclusions, particularly when these weights demonstrate inconsistency or fail to align with established structural biology principles [51]. This article establishes a comprehensive taxonomy of attention-specific faults in binding site identification, supported by experimental validation protocols and mitigation strategies to enhance research reliability.
A Taxonomy of Attention-Specific Faults
Inconsistency and Instability Pitfalls
A fundamental challenge in attention-based binding site identification is the unreliability of attention weights across model variations and training iterations.
- Stochastic Weight Divergence: In high-dimensional biological data, attention mechanisms may fail to converge to consistent interpretations. A comprehensive evaluation of attention-based LSTM models revealed significant inconsistencies in attention scores for individual samples across thousands of model variants with random initializations [51]. The attention mechanisms did not consistently focus on the same feature-time pairs, challenging their faithfulness for clinical decision-making tasks [51].
- Architectural Sensitivity: The consistency of attention weights varies considerably across different neural architectures. Models employing cross-attention between protein and ligand representations, such as ICAN and LABind, demonstrate different stability profiles compared to self-attention models like MolTrans [6] [20].
Table 1: Documented Attention Inconsistency in Binding Site Research
| Model/Context | Inconsistency Manifestation | Impact on Interpretation |
|---|---|---|
| Attention-based LSTM (Clinical Time-Series) [51] | Significant variation in attention scores across 1000 model variants | High unreliability for individual sample explanations |
| Cross-attention Networks (DTI Prediction) [20] | Varying attention weight distributions across binding sites | Reduced statistical significance in binding site identification |
| Multi-head Attention (Protein-Ligand Binding) [50] | Different attention patterns across attention heads | Challenge in consolidating unified binding site prediction |
Interpretability Misconceptions
The assumption that attention weights directly correspond to biological significance represents a critical pitfall in binding site research.
- Attention-Binding Fallacy: High attention weights do not necessarily indicate functional binding regions. While some methods like ICAN have demonstrated that weighted attention sites can statistically correspond to experimental binding sites, this relationship cannot be assumed without rigorous validation [20].
- Contextual Misalignment: Attention mechanisms may highlight regions based on non-binding related patterns in the data. For example, they might focus on chemically reactive groups that don't participate in binding or common molecular substructures with limited relevance to the specific protein interaction [50].
Representation-Linked Failures
The quality and structure of input representations fundamentally impact attention mechanism performance.
- Granularity Mismatch: Inadequate multigranular representation of ligands fails to capture atomic environments, chemogenomic sequences, and mutual effects of local sub-structures simultaneously [50]. Models that separately represent features without integrating multigranular information struggle to interpret how real interaction patterns influence protein-ligand complexes [50].
- Feature Redundancy: Hand-crafted features containing redundant information can bias model training and negatively impact attention weight distribution [52]. This redundancy may lead attention mechanisms to focus on correlated but non-causal features.
Table 2: Representation-Based Pitfalls and Mitigations
| Pitfall Category | Impact on Attention Mechanisms | Documented Solution |
|---|---|---|
| Granularity Mismatch [50] | Incomplete interaction pattern learning | Multigranular representation (DrugMGR) |
| Feature Redundancy [52] | Attention focus on non-predictive features | End-to-end learning (LA6mA/AL6mA) |
| Non-pocket Feature Interference [37] | Attention distraction by non-binding regions | Pocket-guided attention (PGBind) |
Architectural Limitations
Specific architectural designs in attention mechanisms can introduce systematic biases in binding site identification.
- Non-pocket Feature Contamination: When protein features are processed without distinguishing between potential pocket regions and non-pocket regions, attention mechanisms may distribute focus across irrelevant areas [37]. This leads to redundant and unreasonable intra- and inter-graph information interactions, resulting in feature distributions that are not conducive to accurate docking [37].
- Cross-attention Misconfiguration: The selection of context matrices in cross-attention architectures significantly impacts performance. Studies with ICAN demonstrated that plain attention mechanisms decoding drug-related protein context features without protein-related drug context features achieved superior performance [20].
Diagram 1: Architectural pitfalls in attention mechanisms for binding site identification. Red elements indicate fault points where improper implementation can lead to prediction errors.
Experimental Protocols for Fault Detection and Mitigation
Protocol: Evaluating Attention Consistency
Objective: Quantify the stability and reliability of attention weights across multiple training iterations.
- Model Initialization: Initialize 10-100 model instances with identical architecture but different random seeds [51].
- Training Regimen: Train each model instance on the same protein-ligand interaction dataset (e.g., DAVIS, BindingDB) using identical hyperparameters [20].
- Attention Sampling: For a fixed validation set of protein-ligand pairs, extract attention weights from all model instances after convergence.
- Consistency Metric Calculation:
- Compute pairwise correlation coefficients of attention weights across model instances for each protein-ligand pair.
- Calculate coefficient of variation for each residue/atom attention weight across model instances.
- Generate distributions of these metrics across the entire validation set.
- Interpretation: Models with low correlation coefficients (<0.7) and high coefficients of variation (>0.3) indicate significant attention inconsistency [51].
Protocol: Validating Biological Significance of Attention Weights
Objective: Statistically verify whether high-attention regions correspond to experimentally determined binding sites.
- Experimental Binding Site Mapping: Curate a test set of protein-ligand complexes with experimentally validated binding sites from PDBbind or similar databases [50].
- Attention Weight Extraction: Run inference on the curated complexes and extract attention weights for each protein residue.
- Statistical Testing:
- Define high-attention residues as those with weights in the top 20th percentile.
- Calculate the enrichment of experimental binding sites among high-attention residues compared to random expectation using Fisher's exact test.
- Compute precision and recall metrics for attention-based binding site prediction [20].
- Benchmarking: Compare attention-based binding site identification against dedicated pocket prediction algorithms like P2Rank [37].
Protocol: Implementing Pocket-Guided Attention
Objective: Mitigate non-pocket feature contamination by incorporating pocket priors into attention mechanisms.
- Pocket Prior Generation:
- Attention Modulation:
- Incorporate pocket priors as bias terms in attention score calculation:
Adjusted_Attention = Softmax(QK^T/√d + λPocket_Priors) - The scaling factor λ controls the influence of pocket priors on attention distribution.
- Incorporate pocket priors as bias terms in attention score calculation:
- Validation:
- Evaluate docking accuracy with and without pocket-guided attention using metrics like root-mean-square deviation (RMSD) of predicted ligand poses [37].
- Assess the reduction in non-pocket attention focus by quantifying attention mass distributed to known non-binding regions.
Diagram 2: Experimental workflow for implementing pocket-guided attention to mitigate non-pocket feature contamination, showing both the recommended approach (green) and the pitfall pathway (red).
The Scientist's Toolkit: Research Reagent Solutions
Table 3: Essential Computational Tools for Attention-Based Binding Site Research
| Tool/Resource | Function | Application Context |
|---|---|---|
| LABind [6] | Ligand-aware binding site prediction using graph transformers and cross-attention | Predicting binding sites for small molecules and ions in a ligand-aware manner |
| DrugMGR [50] | Multigranular representation learning for binding affinity and region prediction | Comprehensive analysis of protein-ligand complexes using graph, convolution and attention |
| ICAN [20] | Interpretable cross-attention network for drug-target interaction identification | Optimized cross-attention architecture for DTI prediction with statistical interpretability |
| PGBind [37] | Pocket-guided explicit attention learning for blind docking | Enhancing protein features with pocket priors to improve docking accuracy |
| LA6mA/AL6mA [52] | Self-attention mechanisms for DNA modification site prediction | Evaluating different attention architectures (LSTM+Attention vs. Attention+LSTM) |
| PDBbind [50] | Curated database of protein-ligand complexes with binding data | Benchmarking attention mechanisms against experimental binding sites |
Attention mechanisms offer powerful capabilities for binding site identification but require careful implementation to avoid the taxonomic pitfalls outlined in this work. The experimental protocols and toolkits provided herein enable researchers to quantitatively assess attention mechanism reliability and biological relevance. By adopting rigorous validation standards and architectural improvements like pocket-guided attention, the field can advance toward more interpretable and trustworthy predictive models for drug discovery. Future research directions should focus on developing attention-specific regularization techniques and standardized benchmarking frameworks tailored to binding site prediction tasks.
The identification of binding sites represents a critical stage in drug discovery, where the precise interaction between a drug candidate and its biological target determines therapeutic efficacy. Modern research increasingly relies on deep learning models to decipher these complex interactions from vast biomolecular data. The Transformer architecture, with its powerful attention mechanism, has emerged as a foundational tool for this purpose, capable of modeling long-range dependencies in sequences and graphs of molecular structures. However, the full attention mechanism's quadratic computational complexity presents a significant barrier to processing the long sequences and large graphs characteristic of biological data. This challenge necessitates the adoption of optimized attention strategies. This application note details the implementation of two advanced methodologies—sparse attention and causal attention—within the specific context of binding site identification research. We provide a structured framework, including quantitative comparisons, step-by-step experimental protocols, and visualization of core concepts, to empower researchers to integrate these efficient architectures into their computational pipelines.
Sparse Attention Mechanisms
Sparse attention mechanisms address the computational bottleneck of traditional self-attention by strategically reducing the number of query-key pairs calculated. This approach is particularly well-suited for biological sequences and molecular graphs, which often contain redundancies or where long-range dependencies may be limited to specific patterns.
Core Concepts and Variants
- Computational Burden of Full Attention: The standard self-attention mechanism scales quadratically ((O(N^2 \cdot d_{model}))) with sequence length (N), becoming prohibitive for long protein or DNA sequences [53].
- Sparse Query Attention (SQA): This method reduces the number of query heads rather than key/value heads, directly lowering the FLOPs required for the attention score computation. Benchmarks on long sequences (32k-200k tokens) show throughput improvements of up to 3x in compute-bound scenarios like pre-training and fine-tuning, with minimal impact on model quality [53].
- Block Sparse Attention: This approach operates on contiguous blocks of tokens. Its success relies on a "learned similarity gap" ((\Delta\mu)), where the model learns to distinguish relevant from irrelevant blocks based on a signal-to-noise ratio (SNR) given by (\Delta\mu \sqrt{d/(2B)}), where (d) is head dimension and (B) is block size [54].
- Pattern-Based Sparse Attention (DVSA): In specialized domains like speech recognition (with parallels to biomolecular sequences), the Diagonal and Vertical Self-Attention (DVSA) mechanism explicitly selects only important dot-products along the diagonal and top columns of the (QK^T) matrix. This has been shown to improve model performance by 5.7-6.5% while reducing the number of encoder layers by 33% [55].
Quantitative Comparison of Sparse Attention Variants
Table 1: Characteristics of Sparse Attention Mechanisms
| Mechanism | Core Principle | Computational Complexity | Reported Benefits | Best Suited For |
|---|---|---|---|---|
| Sparse Query (SQA) [53] | Reduces the number of Query heads | Direct reduction in FLOPs | ~3x throughput in compute-bound tasks | Model pre-training, fine-tuning, encoder tasks |
| Block Sparse [54] | Attends to contiguous blocks of tokens | (O(N \cdot B)), (B) is block size | Enabled by a learned similarity gap ((\Delta\mu)) | Long-context processing, document understanding |
| DVSA [55] | Selects diagonal & vertical attention patterns | Sub-quadratic | 5.7-6.5% accuracy gain, 33% fewer layers | Sequences with local and global dependencies (e.g., proteins) |
| Sliding Window [53] | Each token attends to a fixed local window | (O(N \cdot k)), (k) is window size | Linear complexity | Sequences where local context is primary |
Causal Attention Mechanisms
Causal attention incorporates principles of causal inference to distinguish true causative biological relationships from spurious correlations, a critical requirement for robust and interpretable drug discovery models.
Core Concepts and Biomedical Applications
- Causal Attention in Drug Synergy (CASynergy): The CASynergy model introduces a causal attention mechanism to differentiate causal genomic features from non-causal noise in predicting cancer drug synergy. This approach significantly enhances generalization on out-of-distribution (OOD) datasets and provides interpretable insights into drug-gene interactions [56].
- Dynamic Causal Reasoning (CafeMed): For medication recommendation, the CafeMed framework uses a Causal Weight Generator (CWG) to transform static causal effects into dynamic modulation weights based on individual patient states. This allows the model to adaptively filter drug conflicts and reduce adverse reaction risks [57].
- Advantages over Correlation-Based Models: Predictive models that rely solely on correlations can be misled by confounding factors (e.g., a gene that is correlated with, but does not cause, a disease phenotype). Causal models are more likely to identify therapeutically successful targets by capturing the underlying disease mechanism [58].
Quantitative Performance in Biomedical Tasks
Table 2: Performance of Causal Attention Models in Biomedical Applications
| Model / Application | Key Metric | Reported Performance | Comparison to Baselines | | :--- | :--- | :--- | : --- | | CASynergy [56] | Area Under the Curve (AUC) | 0.8482 ± 0.007 (DrugCombDB) | Outperformed 5 state-of-the-art models | | CASynergy [56] | Area Under Precision-Recall (AUPR) | 0.8275 ± 0.008 (DrugCombDB) | Outperformed 5 state-of-the-art models | | CafeMed [57] | Medication Recommendation Accuracy | Significantly outperformed SOTA baselines | Superior accuracy with lower drug-drug interaction rates | | Causal Invariance [58] | Robustness to OOD Data | Improved generalization for novel targets | Mitigates overfitting to historical data patterns |
Integrated Implementation Protocols
This section provides detailed methodologies for implementing sparse and causal attention mechanisms in a binding site identification pipeline.
Protocol 1: Implementing Sparse Attention for Protein Sequence Analysis
Objective: To efficiently process long protein sequences for binding site prediction using a sparse attention mechanism.
Materials & Workflow:
Step-by-Step Procedure:
Input Preparation & Embedding:
- Input: Protein sequence (e.g.,
"MAEGE...")of length (N). - Tokenization: Split into residue-level tokens ((N) tokens).
- Embedding: Project each token into a (d{model})-dimensional space using a learned embedding layer, resulting in tensor (X \in \mathbb{R}^{N \times d{model}}).
- Input: Protein sequence (e.g.,
Sparse Attention Computation:
- Option A - Sparse Query Attention (SQA):
- Project (X) into Queries ((Q)), Keys ((K)), and Values ((V)) using separate linear layers.
- Reduce Query Heads: Use fewer query heads ((Hq)) than key/value heads ((H{kv})), e.g., (Hq = H{kv}/4) [53].
- Compute attention scores as ( \text{Attention}(Q_{reduced}, K, V) ).
- Option B - Pattern-Based Sparsity (DVSA-inspired):
- For each attention head, compute the full (QK^T) matrix but only retain values from:
- A diagonal band of width (\pm t) to capture local dependencies.
- The top-(u) columns with the largest aggregate weights to capture specific global dependencies [55].
- Apply softmax only to this sparse subset of scores.
- For each attention head, compute the full (QK^T) matrix but only retain values from:
- Option A - Sparse Query Attention (SQA):
Output & Prediction:
- The output of the sparse attention layer is passed through a feed-forward network and a final linear classification layer.
- Apply a softmax to output logits to predict a probability for each residue being part of a binding site.
Protocol 2: Integrating Causal Attention for Target Identification
Objective: To build a interpretable model for drug-target binding prediction that distinguishes causal molecular features from spurious correlations.
Materials & Workflow:
Step-by-Step Procedure:
Input & Causal Graph Construction:
- Inputs: Multi-modal data including target protein sequences, gene expression profiles of the cell line, and drug molecular fingerprints.
- Construct a Prior Causal Graph: Use biological knowledge databases (e.g., KEGG, Reactome) or causal discovery algorithms (e.g., GIES [57]) to create a graph where nodes are biological entities and edges represent known or hypothesized causal influences.
Causal Attention with Dynamic Weights:
- Encode each entity (e.g., gene, protein domain) from the input data into an embedding (h_i).
- Causal Weight Generator (CWG):
- For each entity (i), calculate its average causal effect on the target outcome (e.g., binding), (\bar{\tau}i = \frac{1}{|M|}\sum{j=1}^{|M|} \tau{ij}), where (\tau{ij}) is the causal effect from the prior graph [57].
- Process this scalar through a small neural network to generate a dynamic modulation vector (wi).
- Modulate the original embedding: (h'i = hi \odot (1 + \alpha \cdot \sigma(wi))), where (\alpha) is a strength hyperparameter (e.g., 0.5) [57].
- Causal Attention Computation: Use the modulated embeddings (h'_i) as input to a standard multi-head attention layer. The model will learn to assign higher attention weights to causally relevant features.
Interpretation & Validation:
- Feature Interpretation: Analyze the attention patterns and the learned modulation vectors (w_i) to identify which molecular features the model deems causally important for binding.
- Experimental Validation: Prioritize predicted binding targets with strong causal support for wet-lab validation (e.g., binding assays).
The Scientist's Toolkit: Research Reagent Solutions
Table 3: Essential Computational Tools for Sparse and Causal Attention Research
| Tool / Resource | Type | Primary Function in Research | Relevance to Binding Site ID |
|---|---|---|---|
| TransformerLens [59] | Software Library | Mechanistic interpretation of Transformer models, including attention head analysis. | Analyzing what patterns a trained model uses to make binding predictions. |
| Sparse Autoencoders (SAEs) [59] | Analysis Technique | Decomposing model activations into interpretable features; shown to work on attention outputs. | Identifying discrete, human-understandable features the model associates with binding sites. |
| GIES Algorithm [57] | Causal Discovery Algorithm | Inferring causal structures from observational data. | Constructing the prior causal graph of biological interactions for causal attention models. |
| ESPnet Toolkit [55] | Software Framework | Open-source end-to-end speech processing toolkit; used in DVSA development. | Reference implementation for efficient, pattern-based sparse attention mechanisms. |
| Knowledge Graphs (KEGG, Reactome) [58] | Data Resource | Structured repositories of biological pathways and interactions. | Providing structured prior knowledge for causal graph construction and model regularization. |
Addressing Attention Collapse and Attention Drift
In the implementation of attention mechanisms for binding site identification research, two significant technical challenges are Attention Collapse and Attention Drift. These instabilities can critically undermine the performance and reliability of deep learning models in drug discovery.
Attention Collapse describes a phenomenon where the softmax function in attention layers produces overly concentrated probability distributions, causing attention to disproportionately focus on a single token or feature while ignoring other relevant information [60]. This occurs due to the high variance sensitivity of softmax, which leads to attention entropy collapse—a state where attention becomes highly concentrated, resulting in training instability and potential gradient explosion [60] [61].
Attention Drift refers to the gradual divergence of visual analysis or reasoning from its original evidential grounding during extended processing [62]. In multimodal AI and visual thinking contexts, this manifests as reasoning chains increasingly relying on language priors or internal heuristics at the expense of fidelity to actual visual input [62]. For binding site identification, this translates to models progressively ignoring crucial structural or chemical information in favor of learned biases.
Table 1: Core Characteristics of Attention Instabilities
| Feature | Attention Collapse | Attention Drift |
|---|---|---|
| Primary Cause | High variance sensitivity of softmax function [60] | Gradual over-reliance on internal priors over observable input [62] |
| Main Manifestation | Excessively concentrated attention distributions [60] | Progressive divergence from perceptual evidence [62] |
| Impact on Training | Training instability, gradient explosion [60] | Performance degradation during extended reasoning [62] |
| Effect on Binding Site ID | Missed relevant residues/atoms [39] | Reduced grounding in structural data [62] |
Quantitative Assessment and Metrics
Monitoring attention instabilities requires specialized metrics that quantify model focus and fidelity. The following measures are essential for diagnosing both collapse and drift phenomena in binding site identification pipelines.
For Attention Collapse, track attention entropy across layers and heads during training. The probability matrix norm serves as a proxy for gradient explosion risk, with sudden increases indicating potential collapse events [60]. Implement variance sensitivity analysis by monitoring how small changes in attention logits affect output distributions.
For Attention Drift, the RH-AUC (Reasoning-Hallucination AUC) metric quantifies the area under the curve traced by model accuracy against hallucination as reasoning chain length increases [62]. The formula is expressed as:
Where R represents reasoning accuracy and H represents hallucination rate at reasoning step T [62]. Additionally, Earth Mover's Distance (EMD) can quantify interpretive divergence in user attention studies [62].
Table 2: Quantitative Metrics for Monitoring Attention Instabilities
| Metric | Formula/Calculation | Threshold | Application |
|---|---|---|---|
| Attention Entropy | -∑(pi × log(pi)) across attention heads | <1.5 indicates collapse risk [60] | Training stability monitoring |
| Probability Matrix Norm | Frobenius norm of attention probability matrix | Sudden increases signal danger [60] | Gradient explosion warning |
| RH-AUC | ∑(R{T(i+1)}-R{T(i)})/2 × (H{T(i+1)}+H{T(i)}) [62] | Higher values preferred | Visual grounding in multimodal AI |
| Cluster Erraticness | E(C)=∑√(1+(Δ(T_i))²) for cluster C [62] | >2.0 indicates high volatility | Process drift detection |
Experimental Protocols
Protocol 1: Preventing Attention Collapse with sigmaReparam
Purpose: Stabilize Transformer training for binding site prediction by preventing attention entropy collapse [61].
Materials:
- Graph Transformer architecture for protein-ligand interaction modeling [39]
- Binding site identification dataset (e.g., DS1, DS2, DS3 benchmark sets) [39]
- Standard deep learning framework (PyTorch/TensorFlow)
Procedure:
- Initialize Baseline Model: Implement a standard graph transformer with softmax attention for binding site prediction [39].
- Implement sigmaReparam: Reparameterize all linear layers with spectral normalization and an additional learned scalar per layer. This controls the Lipschitz constant and prevents attention entropy collapse [61].
- Attention Monitoring: Instrument the model to track attention entropy for each attention head throughout training using:
entropy = -∑(p_i × log(p_i))where p_i are attention probabilities [61]. - Ablation Setup: Train parallel models with and without sigmaReparam under identical conditions.
- Evaluation: Compare training stability, attention entropy patterns, and binding site prediction performance (F1 score, MCC, AUPR) [39].
Technical Notes: sigmaReparam enables training without warmup, weight decay, or layer normalization while maintaining stability—particularly valuable for deep architectures in structural bioinformatics [61].
Protocol 2: Mitigating Attention Drift in Multi-step Binding Analysis
Purpose: Maintain visual grounding during extended binding site analysis through explicit visual evidence rewards [62].
Materials:
- Multimodal architecture for protein-ligand binding prediction (e.g., LABind framework) [39]
- Visual Evidence Reward (VER) implementation [62]
- Protein structure and ligand representation datasets
Procedure:
- Baseline Model Setup: Implement a ligand-aware binding site prediction model using graph transformer with cross-attention between protein and ligand representations [39].
- Drift Monitoring Instrumentation: Implement RH-AUC metric tracking to quantify reasoninghallucination tradeoff during extended analysis [62].
- VER Integration: Incorporate Visual Evidence Reward that explicitly rewards reasoning traces referencing actual structural evidence during training [62].
- Progressive Evaluation: Evaluate binding site prediction accuracy at multiple reasoning chain lengths (T(0) to T(n-1)).
- Cross-modal Alignment: Apply contrastive learning (e.g., InfoNCE loss) to align neural and stimulus embeddings, reducing session-to-session representational drift [62].
Validation: Compare drift metrics and binding site prediction performance (Recall, Precision, F1) against baseline models without anti-drift mechanisms [39].
Protocol 3: Entropy-Stable Attention for Binding Site Identification
Purpose: Implement variance-insensitive attention mechanisms to prevent collapse in binding prediction models [60].
Materials:
- Graph attention network architecture for protein structures [39]
- Entropy-stable attention alternatives (e.g., ReLU or sigmoid activations)
- Binding site residue labeling datasets
Procedure:
- Standard GAT Implementation: Develop a graph attention network for binding site prediction using standard softmax attention [39].
- Entropy-Stable Variants: Implement alternative attention mechanisms with controlled variance sensitivity, such as modified activation functions or normalization schemes [60].
- Variance Sensitivity Analysis: Systematically test how each attention variant responds to logit variance changes.
- Comprehensive Evaluation: Measure binding site prediction performance using standard metrics (AUC, AUPR, MCC) while monitoring training stability and attention entropy [39].
- Ablation Studies: Quantify the contribution of entropy-stable attention to overall model performance and reliability.
Application: This approach is particularly valuable for few-shot learning scenarios with unseen ligands, where stable attention patterns are crucial for generalization [39].
The Scientist's Toolkit
Table 3: Essential Research Reagents and Computational Tools
| Tool/Reagent | Function | Application Context |
|---|---|---|
| sigmaReparam | Stabilizes attention layers via spectral normalization [61] | Preventing attention collapse in deep transformers |
| Visual Evidence Reward (VER) | Rewards explicit visual grounding in reasoning traces [62] | Mitigating attention drift in multimodal analysis |
| RH-Bench | Evaluates reasoning-hallucination tradeoff [62] | Quantifying attention drift in extended analyses |
| Entropy-Stable Attention | Variance-insensitive attention mechanisms [60] | Maintaining attention diversity in binding prediction |
| LABind Framework | Ligand-aware binding site prediction [39] | Cross-attention between protein and ligand representations |
| DriftMaps/DriftCharts | Visual analytics for process drift [62] | Monitoring interpretive drift in visual analytics |
Addressing attention collapse and drift is paramount for reliable binding site identification using deep attention networks. The protocols and metrics presented here provide a systematic approach to stabilizing attention mechanisms in pharmaceutical research. By implementing sigmaReparam to prevent entropy collapse [61], integrating visual evidence rewards to mitigate drift [62], and utilizing entropy-stable attention mechanisms [60], researchers can significantly enhance the robustness and interpretability of binding site prediction models. These stabilized frameworks enable more accurate identification of protein-ligand interaction sites while maintaining scientific rigor throughout extended analytical processes—ultimately accelerating drug discovery pipelines and improving reliability in computational biochemistry applications.
Hyperparameter Tuning for Stability and Performance
In the field of computational biology, particularly for critical tasks like protein-ligand binding site identification, the stability and predictive performance of deep learning models are paramount. Achieving this requires meticulous hyperparameter tuning, a process that moves beyond mere performance maximization to ensure model robustness and reproducibility. For researchers and drug development professionals, this is not an academic exercise but a practical necessity. Models that exhibit high variance in performance with minor parameter shifts can lead to unreliable scientific conclusions and costly dead-ends in the drug discovery pipeline. This document provides detailed application notes and protocols for hyperparameter tuning, framed within a broader research thesis on implementing attention mechanisms for binding site identification. We draw upon contemporary research, such as the LABind model, which utilizes graph transformers and cross-attention mechanisms to learn distinct binding characteristics between proteins and ligands [6] [63]. The methodologies outlined herein are designed to equip scientists with the tools to develop models that are both highly accurate and consistently stable.
Core Hyperparameters and Their Impact on Stability
Hyperparameters control the very nature of the learning process. Selecting appropriate values is crucial for ensuring that a model not only learns effectively but also generalizes well to unseen data, a key requirement for predicting binding sites for novel ligands. The following table summarizes core hyperparameters and their influence on model stability and performance.
Table 1: Core Hyperparameters Impacting Model Stability and Performance
| Hyperparameter | Impact on Performance | Impact on Stability | Considerations for Binding Site Prediction |
|---|---|---|---|
| Learning Rate [64] | Controls the speed of convergence; too high can cause divergence, too low leads to slow training. | A high learning rate causes unstable weight updates and loss oscillation. A low rate provides smooth, stable convergence. | Critical when fine-tuning pre-trained protein language models (e.g., ESM-2 [11]) to avoid catastrophic forgetting of learned features. |
| Batch Size [64] | Affects gradient stability; larger batches can speed up training but may generalize poorly. | Smaller batches introduce noise, which can help escape local minima but increase variance. Larger batches give more stable gradient estimates. | In methods like LABind, a stable batch size is key for learning consistent protein-ligand interaction patterns [6]. |
| Optimizer [64] | Different algorithms (SGD, Adam, RMSprop) affect convergence speed and final accuracy. | Adaptive optimizers like Adam are less sensitive to careful learning rate tuning, offering more stable training out-of-the-box. | The choice influences how effectively the model learns from multiple data sources (e.g., sequence, structure, ligand SMILES). |
| Dropout Rate [64] | Prevents overfitting by randomly disabling neurons; too high can drop useful information. | Acts as a regularizer, directly improving stability and generalization by preventing complex co-adaptations on training data. | Essential for large models processing high-dimensional protein embeddings and PSSM profiles to prevent overfitting on limited structural data [11]. |
| Number of Epochs [64] | Too few leads to underfitting; too many leads to overfitting on the training data. | Early stopping based on validation performance is crucial for training stability, halting before the model begins to overfit. | Monitored using metrics like AUPR, which is well-suited for the imbalanced classification of binding vs. non-binding sites [6]. |
Hyperparameter Optimization Techniques: A Comparative Analysis
A systematic approach to searching the hyperparameter space is required to find the optimal configuration. The choice of strategy represents a trade-off between computational cost and the quality of the solution.
Table 2: Comparison of Hyperparameter Optimization Techniques
| Technique | Core Principle | Advantages | Disadvantages | Best-Suited Scenarios |
|---|---|---|---|---|
| Grid Search [65] | Exhaustively searches over a predefined set of values for all hyperparameters. | Guaranteed to find the best combination within the grid; simple to implement and parallelize. | Computationally intractable for a large number of hyperparameters ("curse of dimensionality"). | Small, well-understood hyperparameter spaces with 2-3 critical parameters. |
| Random Search [65] | Randomly samples combinations from predefined distributions for a fixed number of trials. | More efficient than grid search; better at exploring the hyperparameter space broadly with fewer trials. | May still waste resources on clearly poor combinations; does not learn from past evaluations. | Initial exploration of a larger hyperparameter space where computational budget is limited. |
| Bayesian Optimization [64] [65] | Builds a probabilistic model of the objective function to guide the search towards promising regions. | Highly sample-efficient; learns from past evaluations, balancing exploration and exploitation. | Higher computational overhead per iteration; sequential nature can limit parallelization. | Ideal for expensive-to-train models (e.g., Graph Neural Networks [66] or large transformers) where each training run is costly. |
Application Protocol: Tuning a Binding Site Prediction Model
This protocol provides a step-by-step methodology for hyperparameter optimization, using the LABind model architecture as a concrete example [6]. LABind predicts protein-ligand binding sites by leveraging a graph transformer for protein structure and a cross-attention mechanism to incorporate ligand information from SMILES sequences.
Experimental Workflow
The following diagram illustrates the end-to-end hyperparameter tuning workflow for a binding site prediction model.
Step-by-Step Methodology
Step 1: Define Objective and Evaluation Metrics
- Primary Objective: Identify the optimal set of hyperparameters that maximizes the model's ability to generalize to unseen proteins and, crucially, unseen ligands.
- Key Metrics: Due to the severe class imbalance between binding and non-binding residues, rely on Area Under the Precision-Recall Curve (AUPR) and Matthew's Correlation Coefficient (MCC) as your primary metrics [6]. Accuracy can be misleading. Use the validation set for tuning decisions.
Step 2: Configure the Hyperparameter Search Space
- Based on the core hyperparameters in Table 1, define the ranges to explore. For a model like LABind, which involves training a graph transformer, a search space might include:
- Learning Rate: Log-uniform distribution between
1e-5and1e-3. - Batch Size: Categorical values from
[16, 32, 64], constrained by GPU memory. - Dropout Rate (in attention/FFN blocks): Uniform distribution between
0.1and0.5[64]. - Number of Attention Heads: Categorical values from
[8, 16][64]. - Optimizer: Categorical choice between
['Adam', 'AdamW'].
- Learning Rate: Log-uniform distribution between
Step 3: Select and Execute an Optimization Algorithm
- Recommendation: Employ Bayesian Optimization using a framework like Optuna or Ray Tune [67]. Given the computational expense of training a model like LABind, its sample efficiency is superior to Grid or Random Search.
- Procedure:
- Initialize the Bayesian optimizer with the search space from Step 2.
- For
ntrials (e.g., 50-100, based on computational budget):- Let the optimizer propose a set of hyperparameters.
- Train the model on the training set with these parameters.
- Evaluate the model on the validation set and report the objective metric (e.g., AUPR).
- The optimizer updates its probabilistic model and suggests the next promising set.
Step 4: Evaluate Model Stability
- Stability is as important as peak performance. To assess it:
- Take the top
k(e.g., 5) hyperparameter configurations from the optimization run. - Retrain each configuration from 5 different random weight initializations.
- Record the mean and standard deviation of the validation AUPR for each configuration.
- Take the top
- Selection Rule: The optimal configuration is the one that achieves a high mean AUPR with a low standard deviation, indicating consistent and stable performance regardless of initialization.
Step 5: Final Evaluation
- Train a final model on the combined training and validation data using the selected stable hyperparameter set.
- Report the final, unbiased performance on a held-out independent test set that was not used at any point during the tuning process.
The Scientist's Toolkit: Research Reagent Solutions
The following table details essential software and data "reagents" required for implementing these protocols in binding site identification research.
Table 3: Essential Research Reagents for Hyperparameter Tuning in Binding Site Prediction
| Research Reagent | Type | Function in the Protocol | Example Tools / Sources |
|---|---|---|---|
| Hyperparameter Optimization Framework | Software Library | Automates the search for optimal hyperparameters, implementing algorithms like Bayesian Optimization. | Optuna, Ray Tune, Scikit-learn's RandomizedSearchCV/GridSearchCV [67] [65] |
| Protein Language Model | Pre-trained Model | Provides rich, contextualized feature embeddings from protein sequences, serving as a powerful input to the prediction model. | ESM-2, ProtBert [11] [6] |
| Molecular Language Model | Pre-trained Model | Encodes ligand information (from SMILES strings) into a meaningful representation for the model to learn interactions. | MolFormer [6] |
| Graph Neural Network Framework | Software Library | Facilitates the construction and training of models that operate on graph-structured data, such as protein structures. | PyTorch Geometric, Deep Graph Library |
| Structured Benchmark Datasets | Data | Provides standardized training, validation, and test sets for fair evaluation and comparison of methods. | DS1, DS2, DS3 from LABind [6]; TE46, TE129 for protein-DNA binding [11] |
Advanced Considerations for Attention-Based Architectures
Tuning models that incorporate attention mechanisms, such as the graph transformer and cross-attention in LABind, requires special consideration of architecture-specific parameters.
- Number of Attention Heads: More heads allow the model to focus on different types of relationships simultaneously (e.g., different aspects of protein-ligand interaction) [64]. However, increasing heads also increases computational cost and the risk of overfitting. Tune this parameter carefully, starting with values like 8 or 16.
- Learning Rate Warm-up: Transformer-based models often benefit from a learning rate schedule that includes a warm-up phase, where the learning rate linearly increases from a very low value to the target value over the first few epochs [64]. This stabilizes training in the initial stages.
- Dropout in Attention and FFN Blocks: Applying dropout within the attention mechanisms and feed-forward networks is a critical regularization technique to prevent overfitting and improve stability [64]. The dropout rate is a key hyperparameter to tune.
The following diagram illustrates the flow of information in an attention-based binding site prediction model like LABind, highlighting components governed by key hyperparameters.
For researchers implementing attention mechanisms for binding site identification, efficient management of computational resources and memory constraints is a critical determinant of success. The integration of sophisticated machine learning models, particularly graph transformers and cross-attention mechanisms for protein-ligand interaction prediction, demands strategic approaches to memory allocation and data handling. These approaches must balance the computational intensity of processing three-dimensional protein structures and molecular representations against the practical limitations of available hardware. The LABind methodology exemplifies this challenge, utilizing graph transformers to capture binding patterns within local spatial contexts of proteins while incorporating cross-attention mechanisms to learn distinct binding characteristics [6]. Such architectures require careful consideration of memory binding strategies—the mapping of physical memory to logical addresses—which can be implemented at compile time, load time, or execution time to optimize performance [68]. Within the specific context of binding site identification research, this document provides detailed application notes and experimental protocols to maximize research efficiency while working within substantial memory constraints.
Core Concepts: Memory Binding and Management Strategies
Fundamentals of Address Binding
Address binding, the process of mapping logical addresses to physical memory locations, forms the foundation of efficient memory management in computational research. The appropriate binding strategy directly impacts performance, flexibility, and resource utilization in large-scale bioinformatics workflows [68]. The three primary types of address binding offer distinct trade-offs:
Compile-Time Address Binding: The compiler performs address binding during compilation, linking symbolic addresses with fixed physical memory locations before program execution. This approach offers simplicity and efficiency for functions and global variables with stable memory requirements but lacks adaptability to runtime changes [68].
Load-Time Address Binding: The operating system's loader performs address binding after loading the program into memory, assigning memory addresses based on current system resources. This method provides greater flexibility than compile-time binding, allowing adaptation to available memory and facilitating dynamic libraries [68].
Execution-Time Address Binding (Dynamic Binding): Address binding is postponed until program execution, with memory locations potentially changing throughout runtime. This approach offers maximum flexibility for dynamic memory allocation and is essential for object-oriented programming, polymorphism, and applications with unpredictable memory access patterns [68].
Most modern operating systems, including Windows, Linux, and Unix, practically implement dynamic loading, dynamic linking, and dynamic address binding to optimize resource utilization [68].
Region-Based Memory Management
Region-based memory management, also known as arena allocation, provides an efficient alternative to traditional heap allocation for scientific computing applications. This paradigm allocates objects into distinct regions (partitions, zones, or memory contexts) that can be deallocated simultaneously, significantly reducing overhead associated with individual object deallocation [69].
The implementation offers substantial benefits for binding site prediction pipelines:
Performance Characteristics: Allocation cost per byte is exceptionally low, typically requiring only a comparison and pointer update. Region deallocation is a constant-time operation regardless of the number of objects contained [69].
Memory Safety Considerations: Without additional safeguards, explicit region management can introduce dangling pointers and memory leaks. Region inference techniques, where compilers automatically manage region lifecycle, can provide safety guarantees but may require program restructuring to address "leaks" where regions accumulate dead data before deallocation [69].
Hybrid Approaches: Modern systems often combine regions with complementary techniques. The RC system uses regions with reference counting to guarantee memory safety, while mark-region hybrids combine region-based allocation with tracing garbage collection for optimal memory reclamation [69].
Table 1: Comparative Analysis of Memory Management Strategies
| Strategy | Allocation Performance | Deallocation Performance | Memory Overhead | Use Case Scenarios |
|---|---|---|---|---|
| Compile-Time Binding | Excellent | Excellent | Low | Fixed memory requirements, embedded systems |
| Load-Time Binding | Good | Good | Moderate | Dynamic libraries, modular architectures |
| Execution-Time Binding | Variable | Variable | Variable | Dynamic data structures, unpredictable memory patterns |
| Region-Based Management | Excellent | Excellent (bulk) | Low to Moderate | Object-heavy workloads, short-lived allocations |
| Traditional Heap Allocation | Moderate | Poor (per-object) | Moderate | General-purpose applications |
Application to Binding Site Identification Research
Computational Demands of Attention Mechanisms
The implementation of attention mechanisms for binding site identification creates specific memory challenges that must be addressed through strategic resource management. The LABind architecture exemplifies these demands, incorporating multiple memory-intensive components [6]:
Graph Transformer Operations: Protein structures encoded as graphs require substantial memory for node features (angles, distances, directions) and edge representations (rotations, distances between residues) [6].
Cross-Attention Layers: Learning interactions between protein representations and ligand embeddings necessitates maintaining simultaneous access to both datasets throughout the computation [6].
Multi-Modal Data Integration: Processing diverse input types—including protein sequences, structural features, and ligand SMILES representations—requires efficient memory mapping strategies to prevent bottlenecks [6].
These components generate memory access patterns that benefit significantly from execution-time address binding, which accommodates the unpredictable memory requirements of processing variable-size protein structures and ligand combinations.
Region-Based Management for Molecular Data Structures
Region-based memory management offers particular advantages for binding site prediction pipelines working with molecular data structures:
Bulk Operations: Linked list structures representing molecular pathways or protein residue chains can be deallocated instantly without traversing individual elements, significantly improving performance [69].
Cache Efficiency: Allocating related molecular data (e.g., protein residue features within a structural domain) in the region improves spatial locality and cache utilization [69].
Lifecycle Management: Natural hierarchical relationships in biological data (e.g., residues within proteins within complexes) align well with region nesting strategies, simplifying memory management [69].
Table 2: Memory Allocation Patterns in Binding Site Identification Workflows
| Data Structure | Typical Size Range | Allocation Pattern | Recommended Strategy |
|---|---|---|---|
| Protein Graph Nodes | 100-10,000 nodes | Bulk allocation, incremental addition | Region-based with geometric growth |
| Attention Weight Matrices | O(n²) for sequence length | Single allocation, frequent access | Execution-time binding with memory pooling |
| Ligand Representation Embeddings | Fixed-size vectors | Multiple allocations, simultaneous access | Load-time binding with cache optimization |
| Sequence Encoder Outputs | Variable by protein length | Sequential allocation, sequential processing | Region-based with block allocation |
Experimental Protocols and Methodologies
Protocol: Memory-Efficient Implementation of LABind Architecture
This protocol outlines a memory-optimized implementation strategy for the LABind binding site identification architecture, focusing on practical techniques for managing computational resources.
Initialization Phase
Memory Region Establishment
- Create distinct memory regions for protein graphs, ligand embeddings, and attention mechanisms using region-based allocation.
- Implement the
monotonic_buffer_resourcepattern with initial pool size calculation based on protein complexity metrics [69]. - Configure geometric growth factors for regions (typically 1.5-2.0×) to balance memory efficiency and allocation overhead.
Address Binding Configuration
Processing Phase
Protein Graph Construction
- Allocate graph nodes (residues) and edges (spatial relationships) within a dedicated protein region.
- Implement node spatial features (angles, distances, directions) using structure-of-arrays layout for memory coherence.
- Process edge spatial features (directions, rotations, distances) through block-based allocation to minimize fragmentation.
Cross-Attention Mechanism Optimization
- Employ memory mapping techniques for query-key-value matrices to avoid redundant storage.
- Implement incremental calculation of attention scores for large protein structures to reduce memory footprint.
- Utilize region nesting for multi-head attention, creating subregions for each attention head.
Ligand-Aware Binding Site Prediction
- Process ligand SMILES sequences through MolFormer encoder within a dedicated ligand region [6].
- Implement cross-attention between protein and ligand representations using shared memory buffers.
- Execute multi-layer perceptron classifier with memory reuse strategies for intermediate layers.
Protocol: Resource Monitoring and Optimization Framework
This protocol establishes a systematic approach for monitoring and optimizing memory utilization during binding site identification experiments.
Memory Profiling Procedure
Allocation Pattern Analysis
- Instrument memory allocators to track allocation sizes, frequencies, and lifetimes.
- Profile region utilization efficiency using metrics including occupancy rate and fragmentation index.
- Identify memory hotspots through temporal analysis of allocation patterns.
Performance Benchmarking
- Establish baseline metrics for memory consumption across standard datasets (DS1, DS2, DS3) [6].
- Measure throughput (residues processed/second) against memory utilization to identify optimization candidates.
- Implement regression tests to detect memory leaks during model iteration.
Optimization Techniques
Region Size Tuning
- Conduct parameter sweep to determine optimal initial region sizes for different protein complexity tiers.
- Implement adaptive region resizing based on real-time utilization metrics.
- Establish region pooling strategies for frequently allocated object types.
Memory Binding Strategy Selection
- Analyze data access patterns to determine optimal binding strategies for different workflow components.
- Implement hybrid binding approaches, combining compile-time binding for static model components with execution-time binding for dynamic data structures.
- Validate binding decisions through A/B testing of memory-intensive operations.
Visualization of Workflows and Relationships
Memory Management Strategy Decision Framework
LABind Architecture with Memory Management Integration
The Scientist's Toolkit: Research Reagent Solutions
Table 3: Essential Computational Reagents for Binding Site Identification Research
| Research Reagent | Function | Implementation Example | Resource Considerations |
|---|---|---|---|
| Memory Allocators | Manage dynamic memory allocation for variable-size biological data | monotonic_buffer_resource for region-based management [69] |
Configurable initial size and growth factor |
| Address Binding Managers | Control mapping of logical to physical addresses | OS memory manager for load-time binding [68] | Selection based on data access patterns |
| Graph Processing Frameworks | Handle protein structure graph operations | Graph transformer with hierarchical attention [6] | Optimized for spatial locality |
| Cross-Attention Modules | Learn protein-ligand interaction patterns | Multi-head attention with shared buffers [6] | Memory mapping for large weight matrices |
| Sequence Encoders | Generate representations from biological sequences | Ankh (protein) and MolFormer (ligand) [6] | Pre-trained models with fixed memory footprint |
| Descriptor Heaps | Organize resource views for efficient access | DirectX 12-style descriptor management [70] | Categorization by resource type and frequency |
| Performance Profilers | Monitor memory usage and identify bottlenecks | Instrumented allocators with temporal tracking | Low-overhead data collection |
Effective management of computational resources and memory constraints represents a critical success factor for researchers implementing attention mechanisms in binding site identification. By strategically applying memory binding techniques—selecting among compile-time, load-time, and execution-time binding based on specific data access patterns—and leveraging region-based memory management for object-heavy workloads, research teams can significantly enhance the performance and scalability of their computational pipelines. The protocols and methodologies outlined in this document provide a practical framework for optimizing resource utilization in memory-intensive bioinformatics workflows, particularly those incorporating sophisticated attention mechanisms for protein-ligand interaction prediction. As binding site identification research continues to evolve toward more complex architectures and larger datasets, these fundamental principles of computational resource management will remain essential for advancing drug discovery and structural biology research.
Benchmarking Performance and Real-World Validation
In the field of computational biology, accurately identifying protein binding sites is a critical task for understanding biological functions and accelerating drug discovery. The rapid development of attention-based deep learning models, such as graph attention networks (GATs) and transformers, has significantly improved our ability to predict these sites from protein sequences and structures [43] [18]. However, the performance of these advanced algorithms relies heavily on the appropriate selection of evaluation metrics. In binding site prediction—a classic class imbalance problem where binding residues are vastly outnumbered by non-binding residues—traditional metrics like accuracy can be misleading [71]. This application note focuses on three key metrics that provide robust assessment for such scenarios: the Area Under the Receiver Operating Characteristic Curve (AUC), the Area Under the Precision-Recall Curve (AUPR), and the Matthews Correlation Coefficient (MCC). We detail their implementation, interpretation, and integration within modern attention-based binding site prediction pipelines.
Metric Fundamentals and Mathematical Foundations
Core Definitions and Calculations
Table 1: Fundamental Definitions for Binary Classification Metrics
| Term | Definition | Formula |
|---|---|---|
| True Positive (TP) | Binding sites correctly identified as binding sites | - |
| True Negative (TN) | Non-binding sites correctly identified as non-binding sites | - |
| False Positive (FP) | Non-binding sites incorrectly identified as binding sites | - |
| False Negative (FN) | Binding sites incorrectly identified as non-binding sites | - |
| Precision | Proportion of predicted binding sites that are correct | TP / (TP + FP) |
| Recall (Sensitivity) | Proportion of actual binding sites that are correctly identified | TP / (TP + FN) |
| Specificity | Proportion of actual non-binding sites that are correctly identified | TN / (TN + FP) |
Detailed Metric Profiles
Area Under the ROC Curve (AUC)
- Concept: The AUC measures the model's ability to distinguish between binding and non-binding residues across all possible classification thresholds. It plots the True Positive Rate (Recall) against the False Positive Rate (1 - Specificity) [72].
- Interpretation: An AUC of 1.0 represents a perfect classifier, while 0.5 indicates performance equivalent to random guessing. It is effective in evaluating the overall performance of the model [73] [72].
- Context in Binding Site Prediction: A recent large-scale analysis of evaluation metrics highlighted that AUC is one of the most discriminative metrics for evaluating predictive algorithms, making it a standard in the field [72].
Area Under the Precision-Recall Curve (AUPR)
- Concept: The AUPR measures the model's performance by plotting Precision against Recall at various thresholds [72].
- Interpretation: It is particularly informative for imbalanced datasets common in bioinformatics, where the number of non-binding residues far exceeds binding residues. A high AUPR score indicates that the model maintains high precision (few false positives) as it achieves high recall (finds most true positives) [73] [72].
- Advantage over AUC: In scenarios of severe class imbalance, AUPR is often preferred over AUC because it focuses more on the model's performance on the positive class (binding sites) and is less influenced by the abundance of negative examples [72].
Matthews Correlation Coefficient (MCC)
- Concept: The MCC is a correlation coefficient between the observed and predicted binary classifications. It produces a high score only if the prediction obtains good results in all four categories of the confusion matrix (TP, TN, FP, FN), proportionally to the dataset size and class imbalance [71].
- Interpretation: It ranges from -1 (perfect inverse prediction) to +1 (perfect prediction). An MCC of 0 indicates a prediction no better than random. It is considered a balanced measure that can be used even when the classes are of very different sizes [71] [6].
- Recent Application: Due to its reliability, MCC is increasingly adopted as a key metric in state-of-the-art binding site prediction tools. For instance, the GlycanInsight platform for predicting carbohydrate-binding pockets reports an MCC of 0.63 on experimental structures, underscoring its model's high performance [74].
Comparative Analysis and Metric Selection
Table 2: Metric Comparison for Binding Site Prediction
| Metric | Handles Class Imbalance | Key Strength | Potential Limitation | Ideal Use Case |
|---|---|---|---|---|
| AUC | Moderate | Provides a holistic view of model performance across all thresholds; highly discriminative for comparing algorithms [72]. | Can be overly optimistic when the negative class (non-binding) is massive [72]. | Overall model assessment and initial algorithm screening. |
| AUPR | Strong | Focuses on the model's performance on the positive (binding) class; more informative than AUC for imbalanced data [73] [72]. | Does not consider the performance on the negative class. | Primary metric when the goal is to accurately find binding sites with minimal false positives. |
| MCC | Strong | Considers all confusion matrix categories, providing a balanced summary of model quality on both classes [71]. | Requires a fixed threshold to compute a single value. | Final model evaluation and comparison, especially when a specific classification threshold is chosen. |
Integration with Attention-Based Prediction Workflows
Modern binding site prediction methods heavily utilize attention mechanisms and deep learning. The evaluation metrics discussed are essential for validating these advanced models.
Workflow for Model Training and Evaluation
The following diagram illustrates a generalized protocol for developing and evaluating an attention-based binding site predictor, highlighting where key metrics are applied.
Protocol: Evaluating a Binding Site Prediction Model
Objective: To quantitatively assess the performance of a trained binding site prediction model on a held-out test dataset using AUC, AUPR, and MCC.
Materials:
- Software: Python environment (v3.8+) with scikit-learn, NumPy, SciPy.
- Input Data:
- Ground Truth Labels: A binary vector where each element indicates if a residue is a binding site (1) or not (0).
- Prediction Scores: A vector of continuous probabilities (scores between 0 and 1) output by the model for each residue.
Procedure:
- Prepare Data:
- Ensure ground truth labels and prediction scores are aligned for all residues in the test set.
Calculate AUC:
- Use
sklearn.metrics.roc_auc_score(true_labels, prediction_scores). - This function automatically computes the area under the ROC curve.
- Use
Calculate AUPR:
- Use
sklearn.metrics.average_precision_score(true_labels, prediction_scores). - This computes the area under the precision-recall curve, equivalent to the average precision.
- Use
Calculate MCC:
- Step 4.1: Binarize Predictions. Convert continuous prediction scores into binary labels (0 or 1) using a threshold. A common starting point is a threshold of 0.5.
binary_predictions = (prediction_scores >= 0.5).astype(int) - Step 4.2: Compute MCC. Use
sklearn.metrics.matthews_corrcoef(true_labels, binary_predictions).
- Step 4.1: Binarize Predictions. Convert continuous prediction scores into binary labels (0 or 1) using a threshold. A common starting point is a threshold of 0.5.
Threshold Optimization (Optional but Recommended for MCC):
- To find the optimal threshold for binarization, compute the MCC across a range of thresholds (e.g., from 0.1 to 0.9 in steps of 0.05).
- Select the threshold that yields the highest MCC value on a validation set (not the test set) and use it for final evaluation on the test set.
Reporting Results:
- Report all three metrics together: AUC, AUPR, and MCC. This provides a comprehensive view of model performance from different angles [73] [6] [74].
- Clearly state the threshold used if reporting MCC.
The Scientist's Toolkit
Table 3: Essential Research Reagents and Computational Tools
| Tool/Resource | Type | Primary Function | Relevance to Metric Evaluation |
|---|---|---|---|
| scikit-learn | Software Library | Provides robust implementations for calculating AUC, AUPR, and MCC. | Standardizes metric calculation, ensuring reproducibility and correctness. |
| NABind [73] | Prediction Server | Accurately predicts DNA- and RNA-binding residues using a hybrid deep learning and template-based algorithm. | Benchmarking; its reported performance (e.g., AUC: 0.939, AUPR: 0.728 for DBR) serves as a reference. |
| EquiPNAS [75] | Prediction Algorithm | Uses a protein language model and equivariant graph networks for protein-nucleic acid binding site prediction. | Exemplifies the use of advanced architectures where robust metrics like MCC are crucial for evaluation. |
| LABind [6] | Prediction Algorithm | Predicts binding sites for small molecules and ions in a ligand-aware manner using a graph transformer. | Highlights the application of attention mechanisms and the use of MCC and AUPR for evaluation in multi-ligand scenarios. |
| GlycanInsight [74] | Prediction Platform | Predicts carbohydrate-binding pockets on protein structures. | Demonstrates MCC's utility in reporting performance on specific, challenging prediction tasks (MCC=0.63). |
| DBD/IBD Test Sets | Benchmark Data | Standardized datasets (e.g., TE46, TE129) for protein-DNA/RNA binding site prediction. | Provides a common ground for fair comparison of different models using consistent metrics. |
The integration of powerful attention-based models in binding site prediction necessitates an equally sophisticated approach to evaluation. Relying on a single metric is insufficient for a comprehensive assessment. Instead, a multi-metric approach is strongly recommended. For a holistic evaluation, researchers should report AUC to gauge overall ranking performance, AUPR to critically assess performance on the imbalanced class of binding sites, and MCC to obtain a single, balanced measure of classification quality at the operational threshold. Together, these metrics provide the rigorous and nuanced analysis required to drive progress in the development of reliable computational tools for binding site identification and drug discovery.
Comparative Analysis Against Single-Ligand and Multi-Ligand Methods
The accurate prediction of how small molecules interact with biological targets is a cornerstone of modern drug discovery. Traditional computational methods have largely fallen into two categories: those tailored for specific, single ligands and those designed to handle multiple ligands simultaneously. Each paradigm offers distinct advantages and faces unique challenges. Single-ligand-oriented methods are often highly specialized, yielding high accuracy for their specific target ligand but lacking flexibility. Conversely, multi-ligand-oriented methods offer broader applicability but have historically struggled with accuracy and generalizability, particularly for ligands not encountered during model training. The integration of attention mechanisms and other advanced deep-learning architectures is now driving a paradigm shift, enabling the development of models that are both highly accurate and broadly applicable. This application note provides a comparative analysis of these methodological frameworks, details experimental protocols for their implementation, and demonstrates how attention-based models are advancing the field of binding site identification.
Comparative Performance Analysis of Prediction Methods
Target Prediction Methods for Small Molecules
A 2025 benchmark study systematically evaluated seven target prediction methods for small-molecule drugs using a shared dataset of FDA-approved drugs from ChEMBL. The following table summarizes their algorithms, data sources, and key performance findings [76].
Table 1: Comparative Performance of Small-Molecule Target Prediction Methods [76]
| Method | Type | Source | Algorithm | Database | Key Performance Finding |
|---|---|---|---|---|---|
| MolTarPred | Ligand-centric | Stand-alone | 2D similarity | ChEMBL 20 | Most effective method; Morgan fingerprints with Tanimoto score optimal |
| PPB2 | Ligand-centric | Web Server | Nearest Neighbor/Naïve Bayes/Deep Neural Network | ChEMBL 22 | Performance varies with fingerprint (MQN, Xfp, ECFP4) |
| RF-QSAR | Target-centric | Web Server | Random Forest | ChEMBL 20 & 21 | Performance depends on ECFP4 fingerprint and top similar ligands |
| TargetNet | Target-centric | Web Server | Naïve Bayes | BindingDB | Utilizes multiple fingerprints (FP2, MACCS, E-state, ECFP2/4/6) |
| ChEMBL | Target-centric | Web Server | Random Forest | ChEMBL 24 | Uses Morgan fingerprint |
| CMTNN | Target-centric | Stand-alone | ONNX Runtime | ChEMBL 34 | Employs Morgan fingerprint |
| SuperPred | Ligand-centric | Web Server | 2D/Fragment/3D Similarity | ChEMBL & BindingDB | Uses ECFP4 fingerprint |
The study concluded that MolTarPred was the most effective method overall. Furthermore, it highlighted that model optimization strategies, such as using high-confidence filtering, can reduce recall, making them less ideal for drug repurposing where broad target identification is desired. For MolTarPred specifically, the use of Morgan fingerprints with Tanimoto scores was found to outperform other fingerprint and similarity metric combinations [76].
Binding Site Prediction Methods for Proteins
Independent benchmarking studies have evaluated numerous binding site predictors. A 2024 study introduced the LIGYSIS dataset and compared 13 methods, highlighting the impact of robust pocket scoring schemes [40].
Table 2: Benchmarking Performance of Ligand Binding Site Prediction Methods [40]
| Method | Type | Recall (%) (Pre-LIGYSIS) | Key Finding from Benchmark |
|---|---|---|---|
| fpocket (re-scored by PRANK) | Geometry-based | 60% | Highest recall after re-scoring |
| IF-SitePred | Machine Learning | 39% | Lowest recall; improved by 14% with stronger scoring |
| Surfnet | Geometry-based | Information Missing | Precision improved by 30% with stronger scoring |
| P2Rank | Machine Learning | Information Missing | Relies on Solvent Accessible Surface (SAS) points and random forest |
| DeepPocket | Machine Learning | Information Missing | Uses CNN to re-score and extract pockets from fpocket candidates |
| PRANK | Machine Learning | Information Missing | Used to re-score predictions from other methods (e.g., fpocket) |
The study proposed top-N+2 recall as a universal benchmark metric and emphasized the detrimental effect of redundant binding site predictions on performance. It also demonstrated that re-scoring the predictions of existing methods could lead to significant improvements in both recall and precision [40].
Attention-Based Mechanisms: A Unified Framework
Emerging multi-ligand methods are increasingly leveraging attention mechanisms to overcome the limitations of earlier approaches. These models explicitly incorporate ligand information during training, enabling them to learn generalizable patterns of protein-ligand interaction.
LABind: A Ligand-Aware Binding Site Predictor
LABind is a structure-based method that utilizes a graph transformer to capture binding patterns within the local spatial context of proteins. Its key innovation is a cross-attention mechanism that learns distinct binding characteristics between a protein and a specific ligand. This architecture allows LABind to predict binding sites for small molecules and ions in a ligand-aware manner, even for ligands not present in the training data [6].
The model uses a molecular pre-trained language model (MolFormer) to generate representations from ligand SMILES sequences and a protein pre-trained language model (Ankh) for protein sequence representations. The attention-based learning interaction between these representations enables LABind to effectively integrate ligand information, markedly improving prediction accuracy for diverse ligands, including small molecules, ions, and unseen ligands [6].
CellNEST: Deciphering Cell-Cell Communication Relay Networks
While not a traditional binding site predictor, CellNEST exemplifies the power of attention mechanisms in complex multi-ligand biological problems. It uses a Graph Attention Network (GAT) to identify ligand-receptor pairs and, uniquely, relay networks from spatial transcriptomics data. A relay network involves signal passing across multiple cells via sequences like ligand-receptor-ligand-receptor [77].
CellNEST leverages a GAT encoder with Deep Graph Infomax (DGI) contrastive learning to identify which ligand-receptor pairs are highly probable based on reoccurring patterns of communication in a tissue region. This allows it to move beyond single ligand-receptor pair detection to uncover more intricate, multi-hop communication patterns [77].
Experimental Protocols
Protocol 1: Benchmarking Target Prediction Methods
This protocol is adapted from the comparative study of small-molecule target predictors [76].
- Objective: To systematically evaluate and compare the performance of different target prediction methods using a shared benchmark dataset.
- Materials:
- Database: ChEMBL database (e.g., version 34).
- Software: pgAdmin4 for database querying; stand-alone codes (MolTarPred, CMTNN) or web server access (PPB2, RF-QSAR, etc.).
- Hardware: Standard computer for web servers; local server/high-performance computing for stand-alone codes.
- Procedure:
- Database Preparation:
- Host the ChEMBL database locally (e.g., PostgreSQL).
- Query the
molecule_dictionary,target_dictionary, andactivitiestables. - Retrieve bioactivity records with standard values (IC50, Ki, EC50) below 10,000 nM.
- Filter out non-specific or multi-protein targets and remove duplicate compound-target pairs.
- For high-confidence analysis, apply a filter for a minimum confidence score of 7.
- Benchmark Dataset Curation:
- Collect molecules annotated as FDA-approved drugs from the database.
- Ensure these molecules are excluded from the main database used for prediction to prevent overlap and bias.
- Randomly select a sample (e.g., 100 drugs) for validation.
- Target Prediction Execution:
- For stand-alone codes: Run predictions using the provided scripts and the prepared benchmark dataset.
- For web servers: Submit the query molecules manually or programmatically as per the server's specifications.
- Performance Validation & Analysis:
- Compare predicted targets against known annotated targets from the benchmark dataset.
- Calculate key metrics such as recall, precision, and F1-score.
- Analyze the impact of different parameters (e.g., fingerprint types, similarity metrics).
- Database Preparation:
Protocol 2: Implementing LABind for Binding Site Prediction
This protocol outlines the steps for using the LABind framework [6].
- Objective: To predict protein binding sites for a specific small molecule or ion using the LABind model.
- Materials:
- Input Data:
- Protein Data: Protein sequence (FASTA format) and 3D structure (PDB format). For proteins without experimental structures, use predicted structures from ESMFold or OmegaFold.
- Ligand Data: SMILES string of the query small molecule or ion.
- Software: LABind implementation (source code or web server if available).
- Computational Environment: Python environment with required deep learning libraries (e.g., PyTorch).
- Input Data:
- Procedure:
- Feature Representation:
- Ligand Representation: Input the ligand SMILES sequence into the MolFormer pre-trained model to obtain a molecular representation.
- Protein Representation:
- Input the protein sequence into the Ankh model to obtain sequence embeddings.
- Process the protein structure with DSSP to derive secondary structure features.
- Concatenate the sequence embeddings and DSSP features to form a protein-DSSP embedding.
- Graph Construction:
- Convert the protein 3D structure into a graph where nodes represent residues.
- Node spatial features include angles, distances, and directions from atomic coordinates.
- Edge spatial features include directions, rotations, and distances between residues.
- Integrate the protein-DSSP embedding into the node features of the protein graph.
- Attention-Based Interaction Learning:
- Process the ligand representation and the protein graph representation through the cross-attention mechanism.
- This step allows the model to learn the distinct binding characteristics between the specific protein and ligand.
- Binding Site Prediction:
- Feed the output from the attention layer into a Multi-Layer Perceptron (MLP) classifier.
- The classifier predicts the probability of each residue being part of a binding site.
- Residues with probabilities above a determined threshold are classified as binding site residues.
- Feature Representation:
Visualization of Workflows and Signaling Pathways
Workflow of the LABind Model
Single vs. Multi-Ligand Method Paradigms
The Scientist's Toolkit: Essential Research Reagents and Materials
Table 3: Key Research Reagent Solutions for Binding Site Prediction Research
| Item | Function/Application | Example Use Case |
|---|---|---|
| ChEMBL Database | A manually curated database of bioactive molecules with drug-like properties, containing binding affinities, functional effects, and ADMET data. | Primary source for bioactivity data and ligand-target interactions for training and benchmarking target prediction methods [76]. |
| LIGYSIS Dataset | A curated reference dataset of protein-ligand complexes that aggregates biologically relevant interfaces across biological units of multiple structures from the same protein. | Benchmarking the performance of ligand binding site prediction methods [40]. |
| LILAC-DB | A curated dataset of structures for ligands bound at the protein-bilayer interface. | Studying the distinct chemical properties of ligands that bind to lipid-exposed sites on membrane proteins [78]. |
| RDKit | An open-source cheminformatics toolkit for manipulating chemical structures and calculating molecular descriptors/fingerprints. | Standardizing molecular structures, calculating fingerprints (e.g., Morgan, MACCS), and computing similarity metrics [79]. |
| AutoDock Vina | A widely used program for molecular docking, simulating how a small molecule (ligand) binds to a protein target. | Performing single and multiple ligand simultaneous docking simulations to study binding poses and affinities [80]. |
| GROMACS | A versatile package for performing molecular dynamics (MD) simulations, used to study the physical movements of atoms and molecules over time. | Simulating the stability of protein-ligand complexes and calculating binding free energies using MM-PBSA [80]. |
| ESMFold / OmegaFold | Protein language and deep learning models for predicting protein 3D structures directly from their amino acid sequences. | Generating protein structures for binding site prediction when experimentally determined structures are unavailable [6]. |
| Graph Attention Network (GAT) | A deep learning architecture that operates on graph-structured data, using attention mechanisms to weigh the influence of neighboring nodes. | Core component of models like CellNEST for identifying patterns in spatial transcriptomics data and predicting relay networks [77]. |
Generalization to Unseen Ligands and Protein Structures
The accurate prediction of biomolecular binding sites is a cornerstone of drug discovery, enabling target identification and elucidation of protein function [81]. Traditional computational models often fail to generalize, performing poorly on novel ligands or proteins absent from their training data [82]. This limitation stems from a reliance on topological shortcuts in protein-ligand interaction networks, where predictions are based on a protein's or ligand's number of known interactions rather than their structural or chemical features [82]. Attention mechanisms, which allow models to dynamically focus on the most relevant parts of input data, provide a powerful framework to overcome this challenge [1] [83]. This document details how modern implementations of attention enable binding site prediction models to generalize effectively to unseen ligands and protein structures, complete with quantitative evaluations and practical protocols.
The Generalization Challenge in Binding Site Prediction
A primary obstacle in drug-target interaction prediction is shortcut learning, where models exploit biases in the training data instead of learning the underlying structural principles of binding. State-of-the-art deep learning models have been shown to rely on the topology of the protein-ligand bipartite network, effectively learning that "hub" proteins and ligands with many known interactions are more likely to bind again, irrespective of their chemical properties [82]. Consequently, their performance degrades significantly when predicting interactions for novel (i.e., never-before-seen) protein targets and ligands [82]. This represents a critical roadblock for de novo drug discovery. Attention mechanisms address this by forcing the model to explicitly learn the dependencies between local protein substructures and ligand chemical features, creating a more fundamental understanding of interaction rules that can transfer to new molecular entities [84].
Attention-Based Architectures for Generalized Prediction
Key Architectural Components
Advanced models tackling generalization share several key components that leverage attention:
- Ligand-Aware Cross-Attention: LABind utilizes a cross-attention mechanism between protein residue representations and ligand features. This allows the model to learn distinct binding characteristics for specific ligands, enabling it to predict sites for ligands not present in the training stage [6].
- Pocket-Guided Attention: PGBind enhances protein features by first estimating potential pocket regions and then applying a pocket-guided explicit attention mechanism. This focuses the model's computational resources on areas of the protein most likely to be involved in binding, reducing noise from non-pocket regions and improving accuracy for novel structures [37].
- Unsupervised Pre-training of Representations: AI-Bind pre-trains embeddings for proteins and ligands on large chemical libraries in an unsupervised fashion. This step helps the model learn generalizable representations of chemical structures and amino acid sequences, decoupling it from a dependency on limited binding annotation data [82].
Quantitative Performance Comparison
The table below summarizes the performance of attention-based models against traditional methods on benchmark datasets, highlighting their superior generalization capability.
Table 1: Performance Comparison of Generalized Binding Prediction Methods
| Model | Core Attention Mechanism | Key Generalization Feature | Benchmark Performance (AUPR) |
|---|---|---|---|
| LABind [6] | Graph Transformer with Protein-Ligand Cross-Attention | Ligand-aware binding site prediction | Outperforms single-ligand and multi-ligand oriented methods on DS1, DS2, DS3 datasets. |
| AI-Bind [82] | Not Explicitly Stated | Network-based negative sampling & unsupervised pre-training | Effectively predicts binding for novel proteins and ligands, validated via docking. |
| PGBind [37] | Pocket-Guided Explicit Attention | Plug-and-play module to enhance protein features | Integrated with FABind, achieves state-of-the-art blind docking performance. |
| DeepDTAGen [85] | Multi-task Learning Framework | Predicts affinity & generates drugs via shared feature space | Achieves CI: 0.897 (KIBA), 0.890 (Davis); MSE: 0.146 (KIBA), 0.214 (Davis). |
The following diagram illustrates the core workflow of LABind, integrating multiple attention concepts to achieve ligand-aware generalization.
Experimental Protocols for Validation
Protocol: Evaluating Generalization to Unseen Ligands
Objective: To validate a model's ability to accurately predict binding sites for ligand molecules that were not present in the training dataset.
Materials:
- Benchmark Datasets: Curated datasets such as DS1, DS2, and DS3 [6], or BindingDB [82] [85], split such that specific ligands are exclusively in the test set.
- Computational Environment: High-performance computing node with GPU (e.g., NVIDIA A100 or V100).
- Software: LABind [6] or AI-Bind [82] implementation (available from respective publications).
Procedure:
- Data Preparation:
- Partition the protein-ligand complex data, ensuring that all complexes involving a specific set of ligands are completely excluded from the training and validation sets and placed only in the test set.
- Preprocess input files: Generate protein structure files (e.g., PDB format) and ligand information as SMILES strings [6].
- Model Inference:
- For LABind: Input the protein structure and the SMILES string of the unseen ligand.
- The model will:
- Output & Analysis:
- The model outputs a binary prediction for each protein residue (binding/non-binding).
- Calculate evaluation metrics (Recall, Precision, F1-score, MCC, AUPR) by comparing predictions to the ground truth binding residues from the experimental complex structure [6].
- A high AUPR score on this unseen ligand test set indicates strong generalization capability.
Protocol: Assessing Performance on Predicted Protein Structures
Objective: To determine model robustness when using computationally predicted protein structures instead of experimentally determined ones.
Materials:
- Structure Prediction Tools: ESMFold [6] or OmegaFold [6].
- Dataset: A set of proteins with experimentally determined (ground truth) structures and known ligand binding sites.
Procedure:
- Structure Generation:
- Input the amino acid sequence of the target protein into ESMFold or OmegaFold to generate a 3D structural model.
- Binding Site Prediction:
- Use the predicted protein structure file as input to the trained binding site prediction model (e.g., LABind) along with a ligand SMILES string.
- Validation:
- Compare the binding sites predicted from the in silico model against the known binding sites from the experimental structure of the protein-ligand complex.
- Use the Distance between Predicted and True binding site Centers (DCC) and the Distance to the Closest ligand Atom (DCA) as key quantitative metrics [6].
- Minimal performance degradation when using predicted vs. experimental structures indicates high model robustness [6].
The Scientist's Toolkit
Table 2: Essential Research Reagents and Computational Tools
| Item | Function in Research | Example Use Case |
|---|---|---|
| ESMFold / OmegaFold | Protein structure prediction from amino acid sequence. | Generating 3D structural inputs for proteins lacking experimental structures [6]. |
| MolFormer | Molecular pre-trained language model. | Generating chemical-aware feature representations from ligand SMILES strings [6]. |
| Ankh | Protein pre-trained language model. | Obtaining foundational sequence representations for protein inputs [6]. |
| DSSP | Define Secondary Structure of Proteins. | Extracting structural features (e.g., solvent accessibility) from protein 3D coordinates [6]. |
| P2Rank | Geometry-based pocket prediction. | Estimating potential binding regions on a protein surface to guide attention [37]. |
| Smina | Molecular docking software. | Validating predicted binding sites by assessing docking pose accuracy [6]. |
Attention mechanisms represent a paradigm shift in computational binding site prediction, directly addressing the critical challenge of generalization. By dynamically focusing on relevant protein substructures and ligand chemical features, models like LABind, AI-Bind, and PGBind move beyond memorizing dataset biases to learning the underlying principles of molecular recognition. The protocols and analyses provided herein offer a roadmap for researchers to implement and validate these powerful approaches, accelerating the discovery of novel drug-target interactions in uncharted chemical and biological spaces.
Performance in Molecular Docking and Binding Site Center Localization
The accurate prediction of protein-ligand interactions is a cornerstone of structure-based drug design, serving as a critical filter in the early stages of drug discovery. Traditional molecular docking methods, which rely on physics-based scoring functions and conformational search algorithms, have long been complemented by binding site localization techniques that identify druggable pockets on protein surfaces. Within this domain, the implementation of attention mechanisms represents a paradigm shift, enabling models to focus on critically important residues and atomic interactions that govern molecular recognition. These mechanisms allow computational models to mimic the nuanced selectivity exhibited in biological systems, thereby enhancing prediction accuracy for both binding site identification and ligand pose prediction. This application note provides a contemporary evaluation of docking methodologies, detailed protocols for attention-based binding site prediction, and a standardized framework for their experimental validation.
Performance Benchmarking of Molecular Docking Methods
Recent comprehensive studies have systematically evaluated the performance of traditional and deep learning (DL)-based molecular docking methods across multiple dimensions, including pose prediction accuracy, physical plausibility, and generalization capability. The evaluation encompasses traditional physics-based approaches (Glide SP, AutoDock Vina), generative diffusion models (SurfDock, DiffBindFR, DynamicBind), regression-based models (KarmaDock, GAABind, QuickBind), and hybrid methods (Interformer) that integrate traditional conformational searches with AI-driven scoring functions [86].
Table 1: Comparative Docking Performance Across Benchmark Datasets (Success Rates %)
| Method Category | Specific Method | Astex Diverse Set (RMSD ≤ 2Å) | PoseBusters Set (RMSD ≤ 2Å & PB-Valid) | DockGen Set (Novel Pockets) | Key Characteristics |
|---|---|---|---|---|---|
| Traditional | Glide SP | 85.88 | 83.91 | 67.63 | High physical validity (>94% across sets) [86] |
| Traditional | AutoDock Vina | 81.18 | 72.43 | 54.17 | Balanced performance [86] |
| Generative Diffusion | SurfDock | 91.76 | 39.25 | 33.33 | Superior pose accuracy, moderate physical validity [86] |
| Generative Diffusion | DiffBindFR-MDN | 75.29 | 33.88 | 18.52 | Moderate overall performance [86] |
| Regression-Based | KarmaDock | 22.35 | 6.07 | 1.16 | Poor physical validity [86] |
| Hybrid (AI Scoring) | Interformer | 82.35 | 73.83 | 58.33 | Best balanced performance [86] |
Performance analysis reveals a distinct stratification, with traditional and hybrid methods achieving the highest combined success rates (considering both RMSD ≤ 2Å and physical validity), followed by generative diffusion models, while regression-based methods lag significantly [86]. Under realistic conditions with unbound and predicted protein structures, benchmarking reveals that even the best machine learning-based method achieves only approximately 18% success when both geometric and chemical validity are enforced [87]. This challenges the field to view docking not as a precision predictor but as a powerful statistical filter in drug discovery pipelines [87].
Attention-Based Binding Site Localization: LABind Protocol
The accurate identification of binding sites is a prerequisite for efficient molecular docking. LABind (Ligand-Aware Binding site prediction) represents a state-of-the-art, structure-based method that utilizes a graph transformer and cross-attention mechanism to predict binding sites for small molecules and ions in a ligand-aware manner [6]. This protocol details its implementation.
Principles and Workflow
LABind is designed to address a critical limitation of previous methods: the inability to effectively incorporate specific ligand information during prediction, which hinders generalization to unseen ligands. Its architecture enables it to learn distinct binding characteristics between proteins and ligands through an explicit attention-based interaction mechanism [6].
Step-by-Step Experimental Procedure
Input Preparation and Feature Extraction
Ligand Representation:
- Input the Simplified Molecular Input Line Entry System (SMILES) sequence of the query ligand.
- Process the SMILES sequence using the MolFormer pre-trained molecular language model to generate a comprehensive ligand representation vector [6].
Protein Representation:
- Input the protein's amino acid sequence and its 3D structural coordinates (from experimental data or prediction tools like ESMFold or AlphaFold).
- Generate sequence-based embeddings using the Ankh protein pre-trained language model [6].
- Compute structure-based features using DSSP (Dictionary of Secondary Structure of Proteins) to capture solvent accessibility and secondary structure elements [6].
- Concatenate the Ankh embeddings and DSSP features to form a unified protein-DSSP embedding.
Graph Construction and Spatial Encoding
- Convert the protein structure into a graph where nodes represent residues.
- Define edges between residues based on spatial proximity (e.g., within a specified distance cutoff).
- Node spatial features are derived from atomic coordinates and include angles, distances, and directional information.
- Edge spatial features encode the geometric relationships between residues, including directions, rotations, and distances [6].
- Integrate the protein-DSSP embedding from Step 2 with the node spatial features to create the final protein graph representation.
Attention-Based Interaction Learning and Prediction
- Process the ligand representation and the protein graph representation through a cross-attention mechanism.
- The cross-attention module allows the model to focus on specific protein residues that are most relevant to the given ligand's binding characteristics, learning the distinct interactions between them [6].
- Feed the resulting interaction-aware representations into a Multi-Layer Perceptron (MLP) classifier.
- The MLP performs per-residue binary classification, predicting whether each residue is part of a binding site (defined as residues within a specific distance from the ligand) [6].
Performance and Validation
LABind has demonstrated superior performance over competing methods on benchmark datasets (DS1, DS2, DS3) in terms of AUC (Area Under the ROC Curve) and AUPR (Area Under the Precision-Recall Curve) [6]. Its ligand-aware design enables accurate prediction of binding sites for unseen ligands. Furthermore, applying LABind-predicted binding sites to define docking boxes has been shown to significantly enhance the accuracy of molecular docking poses generated by tools like Smina [6].
Experimental Protocol for Validation
Rigorous validation is essential to assess the performance of docking poses and binding site predictions. The following protocol outlines a standardized evaluation workflow.
Key Validation Metrics
Table 2: Core Metrics for Evaluating Docking and Binding Site Predictions
| Evaluation Dimension | Metric | Description and Interpretation |
|---|---|---|
| Pose Accuracy | Root-Mean-Square Deviation (RMSD) | Measures the average distance between atoms in the predicted pose and the experimental reference structure. An RMSD ≤ 2.0 Å is typically considered a successful prediction [86]. |
| Physical Validity | PoseBusters Validity Checks | Assesses chemical and geometric plausibility, including valid bond lengths/angles, stereochemistry, and the absence of severe protein-ligand steric clashes [86]. |
| Binding Site Center | Distance to True Center (DCC) | Measures the distance between the predicted binding site center and the true binding site center derived from the experimental ligand position [6]. |
| Binding Site Center | Distance to Closest Atom (DCA) | Measures the distance between the predicted binding site center and the closest atom of the bound ligand [6]. |
| Virtual Screening | Enrichment Factor (EF) | Quantifies the method's ability to prioritize true active compounds over decoys in a large library screen [88]. |
Step-by-Step Validation Procedure
- Benchmark Curation: Utilize rigorously curated test sets such as the PoseBusters benchmark (for unseen complexes) and the DockGen dataset (for novel protein binding pockets) to evaluate generalization beyond training data [86].
- Binding Site Localization:
- Run binding site prediction tools (LABind, GrASP, P2Rank) on the prepared protein structure.
- For each predicted site, calculate the DCC and DCA metrics against the known ligand location from the experimental complex [6].
- Molecular Docking:
- Perform docking with the selected methods into the known (crystallographic) binding site or the top predicted site from Step 2.
- Generate multiple poses per ligand and retain the top-ranked pose for evaluation.
- Pose Validation:
- Calculate the RMSD of the top-ranked pose against the experimental ligand conformation.
- Process the pose through the PoseBusters toolkit to determine its physical validity (PB-valid rate) [86].
- Interaction Analysis:
The Scientist's Toolkit: Research Reagent Solutions
Table 3: Essential Computational Tools for Docking and Binding Site Research
| Tool Name | Category | Primary Function | Key Application Note |
|---|---|---|---|
| LABind [6] | Binding Site Prediction | Ligand-aware binding site prediction using graph transformers and cross-attention. | Ideal for predicting sites for novel ligands; enhances docking accuracy when used as a precursor. |
| GrASP [23] | Binding Site Prediction | Graph Attention Site Prediction; identifies druggable pockets via semantic segmentation on protein surface atoms. | Provides high-precision predictions, minimizing wasted computation in downstream docking. |
| PoseBusters [86] | Validation | Toolkit to validate the physical plausibility and chemical correctness of docking poses. | Critical for benchmarking DL-based docking methods that may produce high-RMSD but invalid poses. |
| PLINDER-MLSB [87] | Benchmarking | Benchmark for evaluating docking performance under realistic conditions (unbound/predicted structures). | Provides a sobering, real-world performance estimate versus idealized test sets. |
| ArtiDock [87] | Molecular Docking | Machine learning-based docking method. | Notable for computational efficiency (2–3x faster than AutoDock-GPU); performs best under realistic benchmarks. |
| QuorumMap [87] | Hybrid Docking | Ensemble approach combining multiple docking engines with active learning. | Mitigates limitations of individual methods; explores chemical space more intelligently. |
The SARS-CoV-2 non-structural protein 3 (NSP3) macrodomain, also known as Mac1, is a highly conserved viral domain that is critical for viral pathogenesis and immune evasion [89] [90]. As part of the largest protein encoded by the coronavirus genome, Mac1 functions as an ADP-ribosyl hydrolase, removing ADP-ribose modifications from host proteins that are part of the innate immune response [91] [92]. This enzymatic activity allows the virus to counteract host-mediated antiviral signaling, particularly the interferon response that would otherwise suppress viral replication [89] [93]. Animal studies have demonstrated that catalytic mutations in Mac1 render viruses non-pathogenic, establishing this domain as a promising antiviral target for therapeutic intervention [89] [94].
The Mac1 domain is characterized by a well-defined ADP-ribose binding pocket with an αβα sandwich-like structure, making it amenable to structural biology approaches and drug discovery efforts [92] [93]. Its conservation across all coronaviruses and essential role in virulence further underscore its potential as a target for broad-spectrum anti-coronaviral therapies [91] [94]. This case study explores the application of attention mechanisms and computational approaches for identifying and characterizing Mac1 binding sites, with implications for rational drug design against SARS-CoV-2 and related coronaviruses.
Mac1 Biological Function and Signaling Pathways
The SARS-CoV-2 NSP3 macrodomain plays a pivotal role in the host-virus arms race through its interference with post-translational modifications central to antiviral defense. Mac1 specifically recognizes and hydrolyzes ADP-ribosylation, a modification catalyzed by host poly(ADP-ribose) polymerases (PARPs) that are upregulated in response to viral infection [89] [92]. Several PARP family members, including PARP7, PARP9, PARP10, PARP12, and PARP14, are induced by interferon and contribute to establishing an antiviral cellular environment [91].
The macrodomain's ADP-ribosylhydrolase activity enables SARS-CoV-2 to reverse this host defense mechanism, effectively erasing the ADP-ribosylation signaling that would otherwise lead to viral suppression [91] [93]. This function is particularly important for countering PARP14, which promotes anti-inflammatory interleukin-4-mediated signaling pathways and enhances host interferon responses to viral infection [91]. Through this mechanism, Mac1 helps the virus evade immune detection and supports viral replication and pathogenicity [89] [93].
Table 1: Key Functional Aspects of SARS-CoV-2 NSP3 Macrodomain
| Functional Aspect | Description | Biological Consequence |
|---|---|---|
| Enzymatic Activity | ADP-ribosyl hydrolase | Removes mono-ADP-ribose from modified host proteins |
| Immune Evasion | Counteracts interferon-induced PARP activity | Suppresses innate immune signaling and cytokine production |
| Viral Pathogenesis | Essential for virulence in host organisms | Catalytic mutations render virus non-pathogenic |
| Conservation | Highly conserved across coronaviruses | Potential target for broad-spectrum anticoronaviral drugs |
The critical nature of Mac1 in viral pathogenesis has been firmly established through studies with mutant viruses. For SARS-CoV, mice infected with macrodomain catalytic mutants developed reduced infectivity and virulence, similar to findings with murine hepatitis virus (MHV) where such mutations essentially rendered the virus non-pathogenic [89] [94]. While deletion of Mac1 in SARS-CoV-2 does not completely abolish replication in cell culture, these deletion mutants show increased sensitivity to interferon-γ and do not cause severe disease in animal models, confirming Mac1's role as a virulence factor [93].
Figure 1: Mac1 Role in Viral Immune Evasion Pathway
Computational Approaches for Mac1 Binding Site Identification
Attention Mechanisms in Binding Affinity Prediction
Recent advances in deep learning methodologies have revolutionized the prediction of protein-ligand binding affinity, with attention mechanisms providing particularly powerful insights into binding site characteristics. The CAPLA (Cross-Attention for Protein-Ligand binding Affinity) approach represents a significant innovation by leveraging cross-attention mechanisms to capture mutual interactions between protein-binding pockets and ligands [95]. Unlike traditional methods that process protein and ligand features in detached modules, CAPLA employs sequence-level information from both entities, enabling the model to identify critical functional residues that contribute most to binding affinity through analysis of attention scores [95].
Another multi-modal approach, AttentionMGT-DTA, utilizes graph transformer networks and attention mechanisms to predict drug-target affinity by representing drugs and targets as molecular graphs and binding pocket graphs, respectively [96]. This method employs two attention mechanisms to integrate information between different protein modalities and drug-target pairs, providing both predictive accuracy and interpretability by modeling interaction strengths between drug atoms and protein residues [96]. These attention-based approaches are particularly valuable for Mac1 inhibitor discovery because they can identify subtle binding patterns that might be missed by conventional docking methods.
Virtual Screening and Molecular Docking
Computational docking has been extensively applied to the SARS-CoV-2 Mac1 domain, enabling the screening of vast chemical libraries to identify potential inhibitors. In one comprehensive study, docking of over 20 million fragments prioritized 60 molecules for experimental testing, with 20 confirmed crystallographically to bind to Mac1 [89]. This approach complements experimental fragment screening by exploring a much larger chemical space than empirical libraries, though it faces challenges in predicting weakly-binding fragment geometries with high fidelity [89].
Virtual screening efforts have identified several promising chemotypes against Mac1, including LRH-0003 and Z8539_0072, which inhibit ADP-ribose binding with IC₅₀ values of 1.7 µM and 0.4 µM, respectively [94]. These compounds were discovered through virtual screening followed by medicinal chemistry optimization, demonstrating the utility of computational approaches for initial hit identification [94]. Similarly, knowledge-based screening leveraging the structural homology between Mac1 and human poly(ADP-ribose) glycohydrolase (PARG) has identified shared inhibitor scaffolds that can be optimized for viral macrodomain targeting [92].
Table 2: Computational Methods for Mac1 Binding Site Analysis and Inhibitor Discovery
| Method | Key Features | Application to Mac1 |
|---|---|---|
| CAPLA | Cross-attention mechanism; sequence-based inputs; identifies critical functional residues | Binding affinity prediction; interpretation of key binding site residues |
| AttentionMGT-DTA | Graph transformer; multi-modal attention; molecular graph representation | Drug-target affinity prediction; interaction strength between atoms and residues |
| Molecular Docking | Structure-based virtual screening; large library sampling | Initial hit identification from >20 million compounds [89] |
| Evolutionary Tracing | Comparative sequence analysis; functional residue mapping | Active site homology between Mac1 and human PARG [92] |
Experimental Protocols for Mac1 Inhibitor Validation
Macromolecular Crystallography and Fragment Screening
Crystallographic fragment screening has emerged as a powerful primary method for identifying novel chemical matter against the Mac1 domain. The following protocol outlines the key steps for macromolecular crystallization and fragment screening based on published methodologies [89] [91]:
Protein Expression and Purification
- Construct Design: Express SARS-CoV-2 Mac1 (residues 206-379 or 207-373) with an N-terminal His₆-tag in pDEST17 or pNIC28-Bsa4 vectors [89] [91].
- Expression: Transform E. coli Rosetta BL21(DE3) cells and grow in Terrific Broth at 37°C until OD₆₀₀ₙₘ reaches 1.0-1.2. Induce protein expression with 0.5 mM IPTG at 18°C overnight [91].
- Purification: Lys cells via high-pressure homogenization and purify using immobilized metal affinity chromatography (Ni-Sepharose resin) with stepwise imidazole elution (40-500 mM). Remove His₆-tag with TEV protease and further purify by size exclusion chromatography (Superdex 75) in HEPES buffer (pH 8.0) with 250 mM NaCl and 2 mM DTT [91].
Crystallization and Soaking
- Crystallization: Reproducibly crystallize Mac1 using microseeding in either C2 or P4₃ crystal forms. The P4₃ form with two molecules in the asymmetric unit enables consistent ligand soaking with accessible active sites [89].
- Fragment Soaking: Screen diverse fragment libraries (e.g., 2,683 compounds) by soaking crystals in fragment solutions. Optimize DMSO tolerance to maintain crystal integrity [89].
- Data Collection: Collect X-ray data to ultra-high resolution (0.77-0.85 Å) at physiological temperature to assess conformational heterogeneity around the active site [89].
Biochemical and Biophysical Assays
Multiple complementary assays validate Mac1 inhibitor binding and activity in solution:
HTRF-Based Displacement Assay
- Principle: Homogeneous Time-Resolved Fluorescence (HTRF) measures displacement of an ADP-ribose-conjugated biotin peptide from His₆-tagged Mac1 [91].
- Procedure: Incubate Mac1 with test compounds and ADP-ribose-biotin peptide in appropriate buffer. Add streptavidin-donor and anti-His antibody-acceptor fluorophores. Measure FRET signal after incubation; decreased signal indicates competitive displacement [91].
- Applications: Medium-throughput screening of compound libraries (e.g., FDA-approved drugs, focused chemical sets) for Mac1 inhibitors [91].
Thermal Shift Assay (DSF)
- Principle: Differential Scanning Fluorimetry measures protein thermal stability changes upon ligand binding [93].
- Procedure: Incubate Mac1 with SYPRO Orange dye and test compounds. Gradually increase temperature while monitoring fluorescence. Calculate ΔTₘ (melting temperature shift) relative to apo protein [93].
- Interpretation: Positive ΔTₘ values indicate stabilization through ligand binding, as demonstrated with pyrrolo-pyrimidine inhibitors like MCD-628 [93].
Isothermal Titration Calorimetry (ITC)
- Procedure: Titrate Mac1 protein solution in the sample cell with ligand solution in the syringe. Measure heat changes upon each injection at constant temperature [89].
- Data Analysis: Fit binding isotherm to determine stoichiometry (n), binding constant (Kₐ), and thermodynamic parameters (ΔH, ΔS) [89].
- Utility: Direct measurement of binding affinity and mechanism for fragment validation [89].
Figure 2: Mac1 Inhibitor Validation Workflow
Research Reagent Solutions for Mac1 Studies
Table 3: Essential Research Reagents for SARS-CoV-2 Mac1 Investigation
| Reagent/Category | Specifications | Research Application |
|---|---|---|
| Protein Constructs | SARS-CoV-2 Mac1 (residues 206-379 or 207-373), N-terminal His₆-tag, TEV cleavage site [89] [91] | Protein production for structural and biochemical studies |
| Expression System | E. coli Rosetta BL21(DE3) in Terrific Broth, kanamycin/chloramphenicol selection [91] | Recombinant protein expression |
| Crystallization Screens | Commercial sparse matrix screens (Hampton Research) [91] | Initial crystal condition identification |
| Fragment Libraries | Diverse chemical libraries (e.g., 2,683 fragments for primary screening) [89] | Crystallographic fragment-based drug discovery |
| HTRF Components | ADP-ribose-biotin peptide (ARTK(Bio)QTARK(Aoa-RADP)S), streptavidin-donor, anti-His antibody-acceptor [91] | High-throughput inhibitor screening |
| Cellular Assay Systems | MHV, SARS-CoV-2 with IFN-γ stimulation [93] | Antiviral efficacy assessment in relevant biological context |
Case Study: Pyrrolo-pyrimidine Based Mac1 Inhibitors
A recent case study exemplifies the integrated application of computational and experimental approaches for Mac1 inhibitor development. Researchers identified pyrrolo-pyrimidine-based compounds through structure-based design, beginning with a weak fragment (IC₅₀ = 180 µM) that was optimized into potent inhibitors with demonstrated antiviral activity [93].
The development pipeline involved:
- Initial Fragment Identification: A crystallographic fragment screen identified a pyrrolo-pyrimidine scaffold binding to the Mac1 active site [93].
- Structure-Based Optimization: Researchers synthesized approximately 60 pyrrolo-pyrimidine derivatives, exploring amino acid-based modifications to improve potency [93].
- Lead Compound Characterization: The optimized compound MCD-628 (4a) demonstrated an IC₅₀ of 6.1 µM in AlphaScreen assays and increased Mac1 thermal stability similar to ADP-ribose, confirming target engagement [93].
- Cellular Activity Optimization: To address permeability limitations of the initial lead (containing a carboxylic acid group), researchers developed hydrophobic derivatives through ester and amide couplings with pyridine moieties [93].
- Antiviral Validation: Four optimized compounds (5a, 5c, 6d, and 6e) inhibited murine hepatitis virus (MHV) replication, with 5c and 6e also inhibiting SARS-CoV-2 replication in the presence of IFN-γ - mirroring the phenotype of Mac1-deleted viruses [93].
- Resistance Mapping: Drug-resistant mutations (alanine-to-threonine and glycine-to-valine) emerged in Mac1 when MHV was passaged with compound 5a, confirming target specificity in cellular infection models [93].
This case study demonstrates the successful translation of fragment-based screening to cellularly active inhibitors, validated through a combination of structural biology, biochemical assays, and virological methods. The resulting compounds represent valuable chemical tools for probing Mac1 function and promising starting points for therapeutic development.
The SARS-CoV-2 NSP3 macrodomain presents a promising antiviral target with validated importance in viral pathogenesis and immune evasion. Integrated approaches combining computational prediction with experimental validation have accelerated the identification and optimization of Mac1 inhibitors, with attention mechanisms providing valuable insights into binding site characteristics and interaction patterns. The research protocols and reagent solutions outlined in this case study provide a framework for systematic investigation of Mac1 function and inhibition.
Future research directions should focus on:
- Leveraging deep learning approaches like CAPLA and AttentionMGT-DTA for improved prediction of binding affinities and identification of critical functional residues [95] [96].
- Expanding fragment-based discovery efforts to explore underexplored chemical space around the Mac1 active site [89].
- Advancing promising inhibitor chemotypes, including pyrrolo-pyrimidines, pyrazolines, and other scaffolds, through medicinal chemistry optimization to improve potency and cellular activity [97] [93].
- Investigating the therapeutic potential of Mac1 inhibitors in animal models of coronavirus infection to validate efficacy in vivo.
As the field advances, the integration of computational attention mechanisms with experimental structural and biochemical approaches will continue to enhance our understanding of Mac1 function and accelerate the development of targeted antivirals against SARS-CoV-2 and other coronaviruses with pandemic potential.
Conclusion
The integration of attention mechanisms marks a paradigm shift in binding site identification, offering unprecedented accuracy and interpretability for drug discovery. By moving beyond traditional, ligand-agnostic methods, models leveraging cross-attention and graph transformers can learn distinct protein-ligand interaction patterns, generalizing effectively even to unseen ligands. While challenges such as computational complexity and attention-specific faults like attention collapse require careful management, optimization strategies like sparse attention provide viable solutions. The demonstrated superiority of these models in benchmark studies and real-world applications, from improving molecular docking accuracy to aiding in pandemic-related research, underscores their transformative potential. Future directions will likely involve greater integration with large-scale pre-trained models, enhanced explainability for clinical translation, and application in personalized medicine, solidifying the role of attention-based AI as a cornerstone of next-generation computational biology.
References
- 1. What is an attention mechanism? [https://www.ibm.com/think/topics/attention-mechanism]
- 2. Attention Mechanisms in NLP – Let's Understand the What ... [https://www.wissen.com/blog/attention-mechanisms-in-nlp---lets-understand-the-what-and-why]
- 3. Attention Mechanisms and Their Applications to Complex ... [https://www.mdpi.com/1099-4300/23/3/283]
- 4. Chapter 8 Attention and Self-Attention for NLP [https://slds-lmu.github.io/seminar_nlp_ss20/attention-and-self-attention-for-nlp.html]
- 5. AttentionEP: Predicting essential proteins via fusion ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11652892/]
- 6. LABind: identifying protein binding ligand-aware sites via ... [https://www.nature.com/articles/s41467-025-62899-0]
- 7. A hybrid machine learning model with attention mechanism ... [https://bmcbiol.biomedcentral.com/articles/10.1186/s12915-025-02209-8]
- 8. A protocol for identifying the binding sites of small ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC9006651/]
- 9. What are Query, Key, and Value in the Transformer ... [https://towardsdatascience.com/what-are-query-key-and-value-in-the-transformer-architecture-and-why-are-they-used-acbe73f731f2/]
- 10. Joint fusion of sequences and structures of drugs ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12211918/]
- 11. A novel prediction method for protein-DNA binding sites ... [https://bmcgenomics.biomedcentral.com/articles/10.1186/s12864-025-12196-3]
- 12. Deep attention network for identifying ligand-protein ... [https://www.sciencedirect.com/science/article/abs/pii/S1877750324001613]
- 13. Heterogeneous network drug-target interaction prediction model based on graph wavelet transform and multi-level contrastive learning | Scientific Reports [https://www.nature.com/articles/s41598-025-16098-y]
- 14. PreRBP: Interpretable Deep Learning for RNA-Protein ... [https://www.sciencedirect.com/science/article/abs/pii/S0003269725002076]
- 15. Accurate prediction of protein–ATP binding sites based on ... [https://www.nature.com/articles/s41598-025-25830-7]
- 16. Enhancing the interpretability of transcription factor binding site prediction using attention mechanism - PubMed [https://pubmed.ncbi.nlm.nih.gov/32770026/]
- 17. Machine learning approaches for predicting protein-ligand ... [https://www.frontiersin.org/journals/bioinformatics/articles/10.3389/fbinf.2025.1520382/full]
- 18. Advancing drug discovery with deep attention neural ... [https://www.sciencedirect.com/science/article/pii/S1359644624001922]
- 19. Attention mechanism models for precision medicine - PMC [https://pmc.ncbi.nlm.nih.gov/articles/PMC11136616/]
- 20. ICAN: Interpretable cross-attention network for identifying drug ... [https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0276609]
- 21. ICAN: Interpretable cross-attention network for identifying ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC9591068/]
- 22. SAResNet: self-attention residual network for predicting DNA ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC8579196/]
- 23. Graph Attention Site Prediction (GrASP): Identifying Druggable ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC10402091/]
- 24. Enzyme specificity prediction using cross-attention graph ... [https://www.nature.com/articles/s41586-025-09697-2]
- 25. Enhanced information cross-attention fusion for drug–target ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12453779/]
- 26. Natural Language Processing Methods for the Study of ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11527106/]
- 27. In silico methods for drug-target interaction prediction - PMC [https://pmc.ncbi.nlm.nih.gov/articles/PMC12570315/]
- 28. Artificial Neural Network, Attention Mechanism and Fuzzy ... [https://www.mdpi.com/2673-2688/6/11/281]
- 29. Inside ELRIG's Drug Discovery 2025 [https://www.drugtargetreview.com/article/190237/inside-elrigs-drug-discovery-2025/]
- 30. Advancing drug discovery and development through GPT ... [https://www.sciencedirect.com/science/article/pii/S2666521225000365]
- 31. Protein Secondary Structure Prediction Using 3D Graphs ... [https://arxiv.org/html/2511.13685v1]
- 32. A gated graph transformer for protein complex structure ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC10311325/]
- 33. Stability Oracle: a structure-based graph-transformer ... [https://www.nature.com/articles/s41467-024-49780-2]
- 34. Function prediction of grain proteins based on Graph ... [https://www.sciencedirect.com/science/article/abs/pii/S2212429225017699]
- 35. GTAMP-DTA: Graph transformer combined with attention ... [https://www.sciencedirect.com/science/article/abs/pii/S1476927123001731]
- 36. Unifying sequence-structure coding for advanced protein ... [https://pubs.rsc.org/en/content/articlehtml/2025/sc/d5sc02055g]
- 37. PGBind: pocket-guided explicit attention learning for ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11410380/]
- 38. Machine learning assessment of the binding region as a tool ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC8903148/]
- 39. LABind: identifying protein binding ligand-aware sites via ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12365077/]
- 40. Comparative evaluation of methods for the prediction of ... [https://jcheminf.biomedcentral.com/articles/10.1186/s13321-024-00923-z]
- 41. Exploring the computational methods for protein-ligand ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC7049599/]
- 42. LABind: A ligand-aware approach to protein-ligand binding [https://www.linkedin.com/posts/dr-poornachandra-y-1408b847_zinc-docking-ligands-activity-7365680443897098240-ZFgk]
- 43. Attention is all you need: utilizing attention in AI-enabled drug ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC10772984/]
- 44. Graphein 1.4.0 [https://graphein.ai/]
- 45. Applying graph theory to protein structures: an Atlas of coiled ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC6157074/]
- 46. Protein language model-embedded geometric graphs ... [https://elifesciences.org/articles/92184]
- 47. Multimodal Data Fusion: Key Techniques, Challenges & ... [https://www.sapien.io/blog/mastering-multimodal-data-fusion]
- 48. Multimodal Data Fusion - an overview [https://www.sciencedirect.com/topics/computer-science/multimodal-data-fusion]
- 49. Drug discovery and mechanism prediction with explainable ... [https://www.nature.com/articles/s41598-024-83090-3]
- 50. DrugMGR: a deep bioactive molecule binding method to ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11015954/]
- 51. Pitfalls of Attention-based Model Interpretability for High ... [https://proceedings.mlr.press/v287/yadav25a.html]
- 52. Leveraging the attention mechanism to improve the ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC8575024/]
- 53. Sparse Query Attention (SQA): A Computationally Efficient ... [https://arxiv.org/html/2510.01817v1]
- 54. Statistics behind Block Sparse Attention [https://guangxuanx.com/blog/block-sparse-attn-stats.html]
- 55. DVSA: A Focused and Efficient Sparse Attention via Explicit ... [https://www.sciencedirect.com/science/article/abs/pii/S0167639325001153]
- 56. CASynergy: A causal attention model for interpretable ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12548910/]
- 57. CafeMed: Causal Attention Fusion Enhanced Medication ... [https://arxiv.org/html/2511.14064v1]
- 58. Causal Modeling Helps Machine Learning Find Better ... [https://www.biostatistics.ca/causal-modeling-helps-machine-learning-find-better-drug-targets/]
- 59. Sparse Autoencoders Work on Attention Layer Outputs [https://www.lesswrong.com/posts/DtdzGwFh9dCfsekZZ/sparse-autoencoders-work-on-attention-layer-outputs]
- 60. Variance Sensitivity Induces Attention Entropy Collapse ... [https://aclanthology.org/2025.emnlp-main.421/]
- 61. Stabilizing Transformer Training by Preventing Attention ... [https://machinelearning.apple.com/research/stabilizing-transformer-training]
- 62. Visual Thinking Drift [https://www.emergentmind.com/topics/visual-thinking-drift]
- 63. LABind: identifying protein binding ligand-aware sites via ... [https://pubmed.ncbi.nlm.nih.gov/40830361/]
- 64. The Ultimate Guide to Deep Learning Hyperparameter ... [https://www.blog.trainindata.com/the-ultimate-guide-to-deep-learning-hyperparameter-tuning/]
- 65. Hyperparameter Tuning [https://www.geeksforgeeks.org/machine-learning/hyperparameter-tuning/]
- 66. Hyperparameter optimization and neural architecture ... [https://www.sciencedirect.com/science/article/pii/S0927025625002472]
- 67. AI Model Optimization Techniques for Enhanced ... [https://www.netguru.com/blog/ai-model-optimization]
- 68. Address Binding and its Types [https://www.geeksforgeeks.org/operating-systems/address-binding-and-its-types/]
- 69. Region-based memory management [https://en.wikipedia.org/wiki/Region-based_memory_management]
- 70. Resource binding overview - Win32 apps [https://learn.microsoft.com/en-us/windows/win32/direct3d12/resource-binding-flow-of-control]
- 71. The advantages of the Matthews correlation coefficient (MCC ... [https://bmcgenomics.biomedcentral.com/articles/10.1186/s12864-019-6413-7]
- 72. Quantifying discriminability of evaluation metrics in link ... [https://www.sciencedirect.com/science/article/abs/pii/S096007792500877X]
- 73. Structure-based prediction of nucleic acid binding residues ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC10482303/]
- 74. GlycanInsight: an open platform for carbohydrate-binding ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12110341/]
- 75. EquiPNAS: improved protein–nucleic acid binding site ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC10954458/]
- 76. A precise comparison of molecular target prediction methods [https://pubs.rsc.org/en/content/articlehtml/2025/dd/d5dd00199d]
- 77. CellNEST reveals cell–cell relay networks using attention ... [https://www.nature.com/articles/s41592-025-02721-3]
- 78. A quantitative analysis of ligand binding at the protein-lipid ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11929912/]
- 79. Evaluation of single-template ligand-based methods for the ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12636511/]
- 80. Multiple ligands simultaneous molecular docking and ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11792710/]
- 81. Deep Learning for Predicting Biomolecular Binding Sites of ... [https://pubmed.ncbi.nlm.nih.gov/39995900/]
- 82. Improving the generalizability of protein-ligand binding ... [https://www.nature.com/articles/s41467-023-37572-z]
- 83. Attention Mechanisms and Their Applications to Complex ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC7996841/]
- 84. Generalized Modeling of Enzyme-Ligand Interactions ... [https://pubmed.ncbi.nlm.nih.gov/16948162/]
- 85. DeepDTAGen: a multitask deep learning framework for ... [https://www.nature.com/articles/s41467-025-59917-6]
- 86. Decoding the limits of deep learning in molecular docking for ... [https://pubs.rsc.org/en/content/articlehtml/2025/sc/d5sc05395a]
- 87. Beyond the Benchmark: Rethinking Molecular Docking ... [https://www.receptor.ai/news-and-blogs/beyond-the-benchmark-rethinking-molecular-docking-accuracy]
- 88. Docking strategies for predicting protein-ligand interactions ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11583305/]
- 89. Fragment Binding to the Nsp3 Macrodomain of SARS-CoV-2 ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC7709169/]
- 90. Nsp3 of coronaviruses: Structures and functions of a large ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC7113668/]
- 91. Discovery and Development Strategies for SARS-CoV-2 ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC9965906/]
- 92. Targeting SARS-CoV-2 Nsp3 macrodomain structure with ... [https://www.sciencedirect.com/science/article/pii/S0079610721000079]
- 93. Identification of a series of pyrrolo-pyrimidine-based SARS- ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12153294/]
- 94. Targeting SARS-CoV-2 nonstructural protein 3 [https://www.sciencedirect.com/science/article/abs/pii/S1359644623003483]
- 95. CAPLA: improved prediction of protein–ligand binding ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC9900214/]
- 96. AttentionMGT-DTA: A multi-modal drug-target affinity ... [https://www.sciencedirect.com/science/article/pii/S089360802300641X]
- 97. Exploring pyrazolines as potential inhibitors of NSP3- ... [https://www.nature.com/articles/s41598-024-81711-5]